01: Classification#
Explainable AI for liquefaction
Exercise: ![]() Solution:
Solution: ![]()
Install packages#
!pip3 install scikit-learn pandas
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (1.2.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (1.5.3)
Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.10/dist-packages (from scikit-learn) (1.23.5)
Requirement already satisfied: scipy>=1.3.2 in /usr/local/lib/python3.10/dist-packages (from scikit-learn) (1.10.1)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn) (1.3.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn) (3.2.0)
Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.10/dist-packages (from pandas) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas) (2023.3)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.8.1->pandas) (1.16.0)
!pip install xgboost
Requirement already satisfied: xgboost in /usr/local/lib/python3.10/dist-packages (1.7.6)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from xgboost) (1.23.5)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from xgboost) (1.10.1)
!pip install shap
Requirement already satisfied: shap in /usr/local/lib/python3.10/dist-packages (0.42.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from shap) (1.23.5)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from shap) (1.10.1)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from shap) (1.2.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (from shap) (1.5.3)
Requirement already satisfied: tqdm>=4.27.0 in /usr/local/lib/python3.10/dist-packages (from shap) (4.66.1)
Requirement already satisfied: packaging>20.9 in /usr/local/lib/python3.10/dist-packages (from shap) (23.1)
Requirement already satisfied: slicer==0.0.7 in /usr/local/lib/python3.10/dist-packages (from shap) (0.0.7)
Requirement already satisfied: numba in /usr/local/lib/python3.10/dist-packages (from shap) (0.56.4)
Requirement already satisfied: cloudpickle in /usr/local/lib/python3.10/dist-packages (from shap) (2.2.1)
Requirement already satisfied: llvmlite<0.40,>=0.39.0dev0 in /usr/local/lib/python3.10/dist-packages (from numba->shap) (0.39.1)
Requirement already satisfied: setuptools in /usr/local/lib/python3.10/dist-packages (from numba->shap) (67.7.2)
Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.10/dist-packages (from pandas->shap) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas->shap) (2023.3)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->shap) (1.3.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->shap) (3.2.0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.8.1->pandas->shap) (1.16.0)
Liquefaction#
Durante, M. G., & Rathje, E. M. (2021). An exploration of the use of machine learning to predict lateral spreading. Earthquake Spectra, 37(4), 2288-2314.
Soil liquefaction is a phenomenon that typically occurs in saturated loose sandy soils subjected to rapid loading conditions, such as earthquakes. The generation of excess pore water pressure is a direct consequence of the rapid loading, which can lead to a sudden reduction in the strength and stiffness of the soil. In the presence of gently sloping ground or near the free face of a slope, the occurrence of earthquake-induced liquefaction may generate lateral displacements, known as lateral spreading.
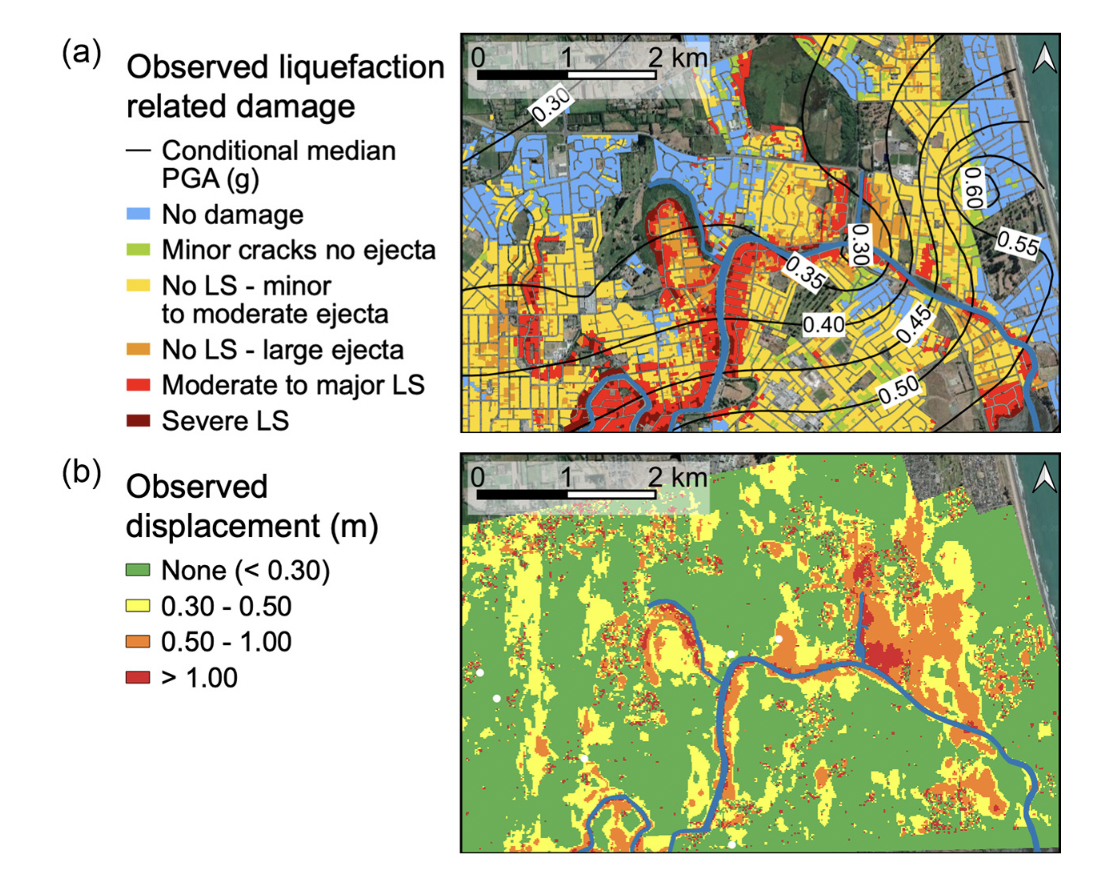
Fig: (a) Observed liquefaction-related damage (data from NZGD, 2013), and (b) lateral spreading horizontal displacement observed from optical image correlation (data from Rathje et al., 2017b) in the Avon River area for the 2011 Christchurch earthquake
Lateral spreading classification#
Durante and Rathje (2021) classified sites that experienced more than 0.3 m displacement as lateral spreading. We now evaluate different factors that influence soil lateral spreading, such as (i) Ground Water Table (ground water closer to surface means more chance of liquefaction), (ii) slope angle (steeper the slope more lateral spreading), (iii) PGA - Peak Ground acceleration (intensity of earthquake shaking), and (iv) elevation (certain sites on high terrace don’t show lateral spreading).
Image credits: Durante and Rathje (2021).
Explore data#
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv('https://raw.githubusercontent.com/kks32-courses/sciml/main/lectures/01-classification/RF_YN_Model3.csv')
df.head()
| Test ID | GWD (m) | Elevation | L (km) | Slope (%) | PGA (g) | Target | |
|---|---|---|---|---|---|---|---|
| 0 | 182 | 0.370809 | 0.909116 | 0.319117 | 5.465739 | 0.546270 | 0 |
| 1 | 15635 | 1.300896 | 1.123009 | 0.211770 | 0.905948 | 0.532398 | 0 |
| 2 | 8292 | 1.300896 | 0.847858 | 0.195947 | 0.849104 | 0.532398 | 0 |
| 3 | 15629 | 1.788212 | 2.044325 | 0.115795 | 0.451034 | 0.542307 | 0 |
| 4 | 183 | 1.637517 | 2.003797 | 0.137265 | 0.941866 | 0.545784 | 1 |
Filtering for features#
Remove any feature in the dataset that we don’t want to include in the training process.
df = df.drop(['Test ID', 'Elevation'], axis=1)
df.head()
| GWD (m) | L (km) | Slope (%) | PGA (g) | Target | |
|---|---|---|---|---|---|
| 0 | 0.370809 | 0.319117 | 5.465739 | 0.546270 | 0 |
| 1 | 1.300896 | 0.211770 | 0.905948 | 0.532398 | 0 |
| 2 | 1.300896 | 0.195947 | 0.849104 | 0.532398 | 0 |
| 3 | 1.788212 | 0.115795 | 0.451034 | 0.542307 | 0 |
| 4 | 1.637517 | 0.137265 | 0.941866 | 0.545784 | 1 |
X = df.copy(deep=True)
y = df['Target']
y.head()
0 0
1 0
2 0
3 0
4 1
Name: Target, dtype: int64
Training, testing and validation#
When developing a machine learning model, it is common practice to divide the available data into three subsets - training, validation, and testing. This is done to properly assess model performance and generalizability.
The training set is used to fit the parameters of the model. The majority of the data, typically 60-80%, is allocated for training so that the model can learn the underlying patterns.
The validation set is used to tune any hyperparameters of the model and make architectural choices. For example, it helps decide the number of hidden layers and units in a neural network. Typically 20% of data is used for validation.
The test set provides an unbiased evaluation of the fully-trained model’s performance. It is critical for getting an accurate estimate of how the model will work on new unseen data. Usually 20% of the data is reserved for testing.
The splits should be made randomly while ensuring the class distribution is approximately balanced across all sets. No data from the validation or test sets should be used during training. This prevents overfitting and ensures the evaluation reflects real-world performance.
X
| GWD (m) | L (km) | Slope (%) | PGA (g) | Target | |
|---|---|---|---|---|---|
| 0 | 0.370809 | 0.319117 | 5.465739 | 0.546270 | 0 |
| 1 | 1.300896 | 0.211770 | 0.905948 | 0.532398 | 0 |
| 2 | 1.300896 | 0.195947 | 0.849104 | 0.532398 | 0 |
| 3 | 1.788212 | 0.115795 | 0.451034 | 0.542307 | 0 |
| 4 | 1.637517 | 0.137265 | 0.941866 | 0.545784 | 1 |
| ... | ... | ... | ... | ... | ... |
| 7286 | 1.631807 | 0.352863 | 0.839925 | 0.420179 | 0 |
| 7287 | 1.269804 | 0.584068 | 0.050562 | 0.416337 | 0 |
| 7288 | 1.500085 | 0.441609 | 0.360601 | 0.420179 | 0 |
| 7289 | 1.775998 | 0.353520 | 1.204065 | 0.420179 | 0 |
| 7290 | 1.389241 | 0.506993 | 0.990708 | 0.416337 | 0 |
7291 rows × 5 columns
We are going to use the train_test_split function twice to split the data into training + validation and testing. Then, we split the training + validation into training and validation. We retrain the target values for now, so we can check how good is our prediction.
X_train_target, X_val_test_target, y_train, y_val_test = train_test_split(X, y, test_size=0.2)
X_test_target, X_val_target, y_test, y_val = train_test_split(X_val_test_target, y_val_test, test_size=0.2)
X_val_target
| GWD (m) | L (km) | Slope (%) | PGA (g) | Target | |
|---|---|---|---|---|---|
| 4842 | 2.465091 | 1.366231 | 1.337589 | 0.402446 | 0 |
| 311 | 2.220278 | 0.697772 | 1.524962 | 0.485805 | 0 |
| 3988 | 2.223850 | 0.525416 | 2.593247 | 0.490235 | 1 |
| 4773 | 1.673375 | 2.422799 | 1.074945 | 0.371233 | 0 |
| 323 | 2.934342 | 0.669136 | 2.542488 | 0.481632 | 0 |
| ... | ... | ... | ... | ... | ... |
| 2823 | 1.719638 | 2.359258 | 0.000000 | 0.401707 | 1 |
| 2806 | 1.618360 | 2.329173 | 0.000000 | 0.401707 | 1 |
| 5563 | 2.897944 | 0.507353 | 0.394654 | 0.421380 | 0 |
| 6361 | 1.885435 | 0.081483 | 0.190712 | 0.426110 | 1 |
| 1745 | 2.698600 | 2.163888 | 1.044354 | 0.368342 | 0 |
292 rows × 5 columns
X_train = X_train_target.drop(['Target'], axis=1)
X_test = X_test_target.drop(['Target'], axis=1)
X_val = X_val_target.drop(['Target'], axis=1)
X_test.head()
| GWD (m) | L (km) | Slope (%) | PGA (g) | |
|---|---|---|---|---|
| 182 | 1.995111 | 0.720363 | 1.056944 | 0.419531 |
| 6863 | 1.642848 | 0.287636 | 0.744498 | 0.449792 |
| 638 | 2.408738 | 1.675044 | 0.882258 | 0.495766 |
| 4770 | 1.853496 | 0.561542 | 0.044951 | 0.429180 |
| 4452 | 1.826260 | 0.518457 | 0.481842 | 0.418497 |
y_test.head()
182 0
6863 0
638 1
4770 1
4452 0
Name: Target, dtype: int64
Decision tree classifier#
Classification: Decision Trees#
Classification is the task of predicting a categorical target variable based on input data. There are two main types of classification:
Binary classification: The target variable has two possible classes, often labeled 0 and 1. The goal is to predict which of the two classes an input belongs to. Examples include spam detection, disease diagnosis, etc.
Multi-class classification: The target variable has more than two possible discrete values or classes. The goal is to predict the specific class an input belongs to out of the multiple choices. Examples include image recognition, document categorization, etc.
A decision tree is a flowchart-like structure where each internal node represents a test on a feature (e.g., “is feature A > 5?”), each branch represents an outcome of the test, and each leaf node represents a class label. A decision tree is a supervised learning model used for both binary and multi-class classification. It works by recursively partitioning the input space into smaller subspaces based on the value of different predictor variables. The goal is to create leaf nodes that contain cases with similar values of the target variable.
The process of learning a decision tree involves selecting features and split points that best separate the classes, based on a criterion such as information gain or Gini impurity. It continues until a stopping criterion is met, like reaching a maximum depth or a minimum number of samples per leaf.
The structure of a decision tree consists of:
Root node: This is the topmost node in the tree and contains the full dataset.
Internal nodes: These represent points where the data is split based on values of predictor variables.
Branches: These connect the internal nodesbased on possible values of predictors.
Leaf nodes: These represent the final classifications or predictions.
Decision trees can handle both categorical and continuous predictors.
Some key advantages of decision trees are:
Interpretability - The tree structure and rules are easy to understand.
Non-parametric - No assumptions about data distribution.
Handles nonlinear relationships - By partitioning data recursively.
Handles categorical variables - No need for dummy coding.
GINI Impurity#
Gini impurity is used to evaluate how good a split is by calculating the impurity of the subsets resulting from the split. A lower Gini score means that the split is separating the classes well. It quantifies the disorder or uncertainty within a set of data.
The Gini impurity for a binary classification is calculated as: $\(Gini(t)=1−\sum(p_i)^2\)$
where \(p_i\) is the probability of class \(i\) in the set.
Decision Tree splitting#
A decision tree decides a split by selecting a feature and a value to divide the dataset into two or more homogenous subsets, according to a certain criterion. The ultimate goal is to find the splits that produce the purest subsets, meaning that each subset ideally contains data points from only one class. Here’s how it works:
Selection of Criteria: The method used to decide a split depends on the criterion being used. Common criteria for classification tasks include Gini Impurity, Information Gain, and Chi-Squared. For regression tasks, variance reduction is often used.
Evaluate Each Feature and Potential Split: For each feature in the dataset, the algorithm calculates the criterion’s value for every potential split point. Split points can be the actual values of a continuous feature or different categories of a categorical feature.
Choose the Best Split: The algorithm selects the feature and split point that produces the subsets with the highest purity according to the chosen criterion. For example: In the case of Gini Impurity, the best split minimizes the impurity. In the case of Information Gain, the best split maximizes the gain.
Create Subsets: Once the best split has been identified, the dataset is divided into subsets according to the chosen feature and split point.
Repeat: Steps 1-4 are repeated recursively on each of the subsets until a stopping criterion is met, such as reaching a certain tree depth or the subsets being pure enough.
Example Using Gini Impurity#
For each feature, consider all possible values for splitting.
Choose the split that results in the lowest weighted Gini Impurity.
Calculate the Gini Impurity for each possible split as:
Divide the dataset accordingly and continue the process.
In the context of decision trees, the splitting process is essential as it helps the model generalize the pattern from the training data, enabling accurate predictions or classifications for unseen data. It’s the core step in building the tree, and different algorithms might have variations in the splitting procedure.
Decision tree with SciKit Learn#
Scikit-learn, often referred to as sklearn, is one of the most popular libraries for machine learning in Python
from sklearn import tree
from sklearn.metrics import accuracy_score
clf = tree.DecisionTreeClassifier(max_depth=3)
clf.fit(X_train, y_train)
DecisionTreeClassifier(max_depth=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_depth=3)
print('Training score: %.2f%%' %(clf.score(X_train, y_train) * 100))
print('Validation score: %.2f%%' %(clf.score(X_val, y_val) * 100))
print('Testing score: %.2f%%' %(clf.score(X_test, y_test) * 100))
Training score: 68.54%
Validation score: 64.04%
Testing score: 67.44%
accuracy_score(y_test, clf.predict(X_test))
0.6743787489288775
Prediction#
clf.predict(X_test)[4]
0
Visualizing a decision tree#
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(20, 20))
tree.plot_tree(clf,
feature_names =['GWD (m)', 'L (km)', 'Slope (%)', 'PGA (g)'],
class_names=['Liquefaction', 'No liquefaction'],
filled = True)
fig.show()
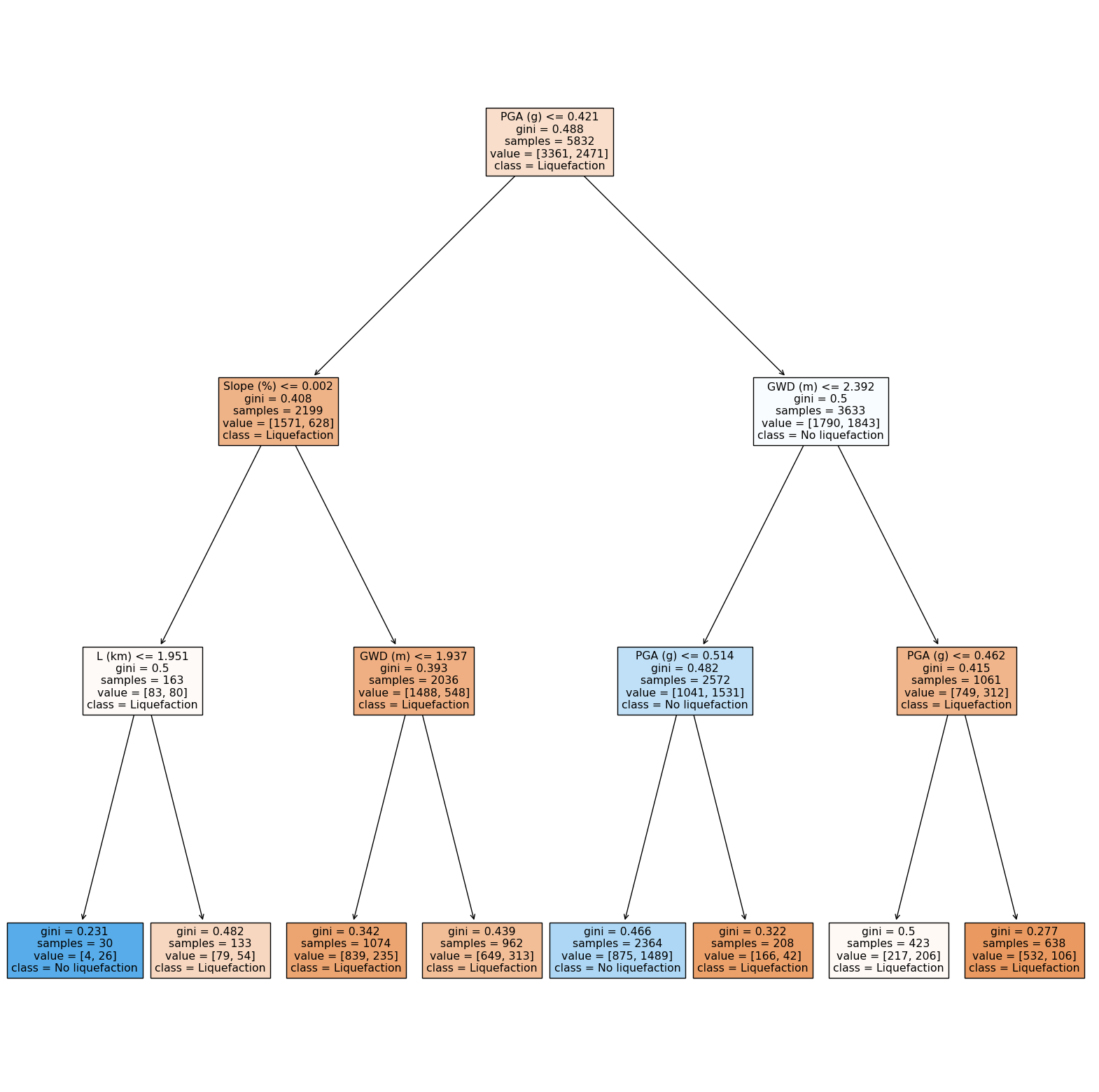
Update model#
We increase the max_depth to 7 so we have a better fit.
💡 Try varying the
max_depthfrom 5 - 9.
clf = tree.DecisionTreeClassifier(max_depth=7)
clf.fit(X_train, y_train)
DecisionTreeClassifier(max_depth=7)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_depth=7)
print('Training score: %.2f%%' %(clf.score(X_train, y_train) * 100))
print('Validation score: %.2f%%' %(clf.score(X_val, y_val) * 100))
print('Testing score: %.2f%%' %(clf.score(X_test, y_test) * 100))
Training score: 77.97%
Validation score: 72.95%
Testing score: 74.98%
Metrics#
A confusion matrix is commonly used to evaluate the performance of a machine learning classification model. It is an N x N matrix that summarizes how well the model classifies examples into N distinct classes.
The confusion matrix compares the actual target values to the predicted values. It shows the number of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) for each class. A higher count of TP and TN indicates better model performance, while more FP and FN points mean the model is making errors.
Key evaluation metrics derived from the confusion matrix are accuracy, recall (or true positive rate), and precision. Accuracy measures the overall percentage of correct classifications, treating false positives and false negatives equally.
Recall calculates the fraction of positive cases that are correctly classified as positive. It looks across the rows of the confusion matrix. Precision looks down the columns, measuring the fraction of positive predictions that are true positives. High precision means few false positives.
For binary classification, the formulas for these metrics are:
Accuracy = \((TP + TN)/(TP + TN + FP + FN)\)
Recall = \(TP/(TP + FN)\) = TP/(all positive data)
Precision = \(TP/(TP + FP)\) = TP/(all positive predictions)
The confusion matrix and these metrics provide a quantitative assessment of model performance on a classification problem. They highlight the types of errors and allow targeted improvement.
Precision:
Definition: Ratio of correctly predicted positive observations to the total predicted positives.
Formula: $\( \text{Precision} = \frac{\text{True Positive}}{\text{True Positive} + \text{False Positive}} \)$
Interpretation: Of all instances labeled as positive, how many were actually positive?
Recall (Sensitivity):
Definition: Ratio of correctly predicted positive observations to all actual positives.
Formula: $\( \text{Recall} = \frac{\text{True Positive}}{\text{True Positive} + \text{False Negative}} \)$
Interpretation: Of all actual positive instances, how many were correctly labeled?
Trade-off:
Precision and recall often have a trade-off.
F1 score combines both: $\( F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} \)$
Decision Trees and Precision-Recall:
Decision trees use feature thresholds to make decisions.
Adjusting decision thresholds can influence precision and recall.
Precision-Recall curves visualize the trade-off.
Note: Consider both precision and recall for imbalanced datasets or when false positives and negatives have different implications.
Researchers commonly use receiver operating characteristic (ROC) curves to evaluate the performance of machine learning classification models. A ROC curve plots the true positive rate (TPR) against the false positive rate (FPR) for different classification probability thresholds. The TPR, also called recall, represents the percentage of positive cases correctly classified. The FPR represents the percentage of negative cases incorrectly classified as positive.
The FPR represents the fraction of the negative points that are incorrectly classified as positive (FPR = FP/(FP + TN) = FP/(all negative data)). An ideal classifier will have a ROC curve that passes through the top left corner, with a TPR of 1 and FPR of 0. A random classifier will have a ROC curve along the diagonal line where TPR equals FPR. Less accurate models have curves closer to the diagonal, while more accurate models have curves further up and left.
The area under the ROC curve (AUC) quantifies the model’s performance. Larger AUC values indicate better classification, with a maximum of 1. AUC values near 0.5 imply performance equal to a random classifier.
Although designed for binary classification, ROC analysis can be extended to multi-class problems using a one-vs-rest approach. This involves creating a binary classifier for each class against the rest. The per-class ROC curves are averaged, weighting by class size, to produce an overall curve.
Plot metrics#
Confusion Matrix#
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix(y_true, y_pred, normalize=False):
cm = confusion_matrix(y_true, y_pred)
if normalize:
cm = cm.astype('float') / len(y_true)
cm = np.round(cm, decimals=3)
fig, ax = plt.subplots()
im = ax.imshow(cm, cmap=plt.cm.Blues)
ax.set_xticks([0,1])
ax.set_yticks([0,1])
ax.set_xticklabels(['No','Yes'])
ax.set_yticklabels(['No','Yes'])
ax.set_xlabel('Predicted')
ax.set_ylabel('True')
for i in range(2):
for j in range(2):
text = ax.text(j, i, cm[i, j], ha="center", va="center", color="black")
ax.set_title('Confusion Matrix')
fig.tight_layout()
plt.show()
# make prediction on test set
y_pred = clf.predict(X_test)
# plot confusion matrix for test set
plot_confusion_matrix(y_test, y_pred, normalize=True)
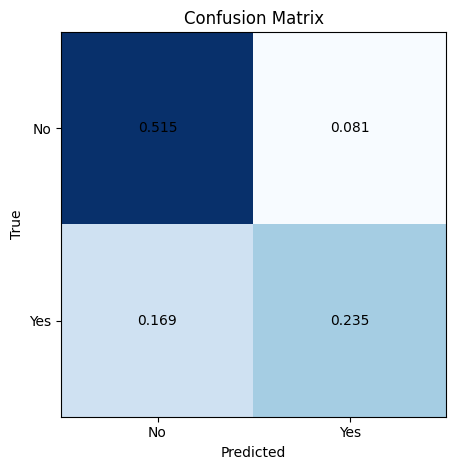
# make prediction on training set
y_pred_train = clf.predict(X_train)
# plot confusion matrix for training set
plot_confusion_matrix(y_train, y_pred_train, normalize = True)
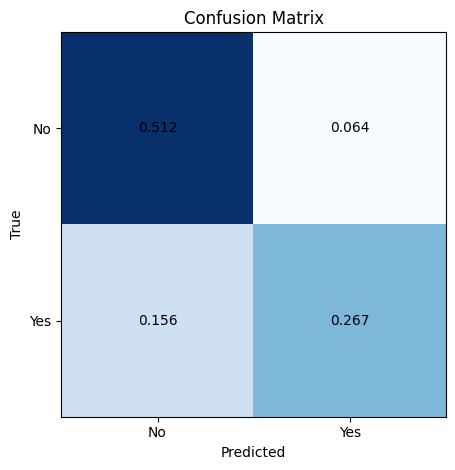
ROC#
from sklearn.metrics import cohen_kappa_score, roc_curve, roc_auc_score, accuracy_score, classification_report, make_scorer
def plot_roc_cur(fper, tper):
plt.plot(fper, tper, color='orange', label='ROC')
plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
probs = clf.predict_proba(X_test)[:, 1]
fper, tper, thresholds = roc_curve(y_test, probs)
plot_roc_cur(fper, tper)
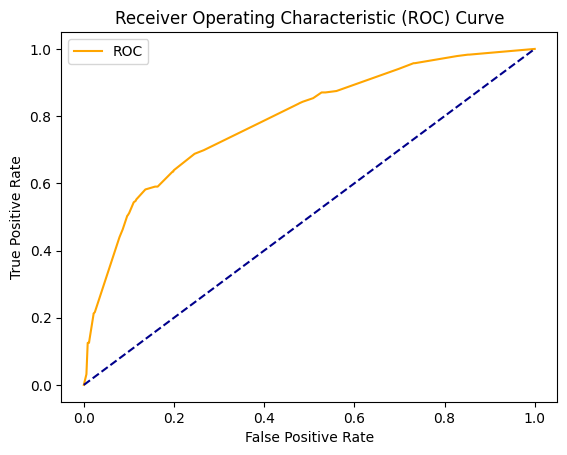
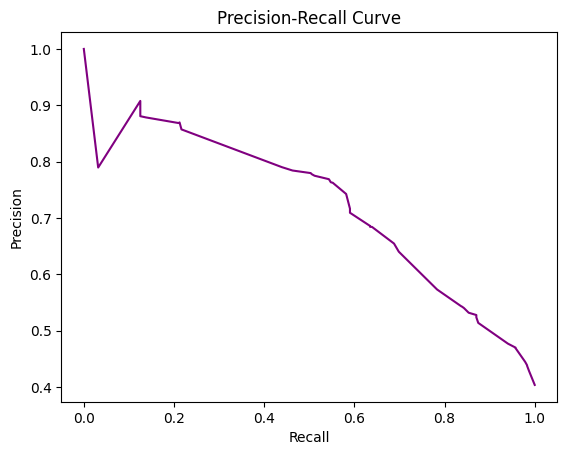
Precision recall curve#
A precision-recall curve (PR curve) is another common technique used to evaluate the performance of classification models, alongside ROC curves. The PR curve plots precision vs. recall at different thresholds.
Precision measures the fraction of positive predictions that are true positives, while recall (same as true positive rate) measures the fraction of actual positives correctly predicted as positive.
A PR curve shows the tradeoff between precision and recall. High recall means detecting most of the positive cases, but potentially more false positives. High precision means positive predictions are more accurate, but some positives may be missed.
The curve is generated by varying the classification threshold and plotting precision and recall at each threshold. A perfect classifier will have a horizontal line at precision = 1. Random guessing produces a diagonal line.
The area under the PR curve (AUC) summarizes the overall performance. Higher AUC indicates better classification performance.
Advantages of PR curves:
Better visualization of performance for imbalanced classes. ROC curves can hide poor performance on the minority class.
Directly shows precision-recall tradeoff important for many applications.
Can be more useful than ROC curves when the positive class is more important.
from sklearn.metrics import precision_recall_curve, roc_curve
import matplotlib.pyplot as plt
#use logistic regression model to make predictions
y_score = clf.predict_proba(X_test)[:, 1]
#calculate precision and recall
precision, recall, thresholds = precision_recall_curve(y_test, y_score)
#create precision recall curve
fig, ax = plt.subplots()
ax.plot(recall, precision, color='purple')
#add axis labels to plot
ax.set_title('Precision-Recall Curve')
ax.set_ylabel('Precision')
ax.set_xlabel('Recall')
#display plot
plt.show()
Summary of decision trees#
Pros and Cons
Pros: Simple to understand and visualize, able to handle categorical and numerical data.
Cons: Prone to overfitting, especially when the tree is deep, leading to poor generalization to unseen data. A small change in the data can lead to a very different tree.
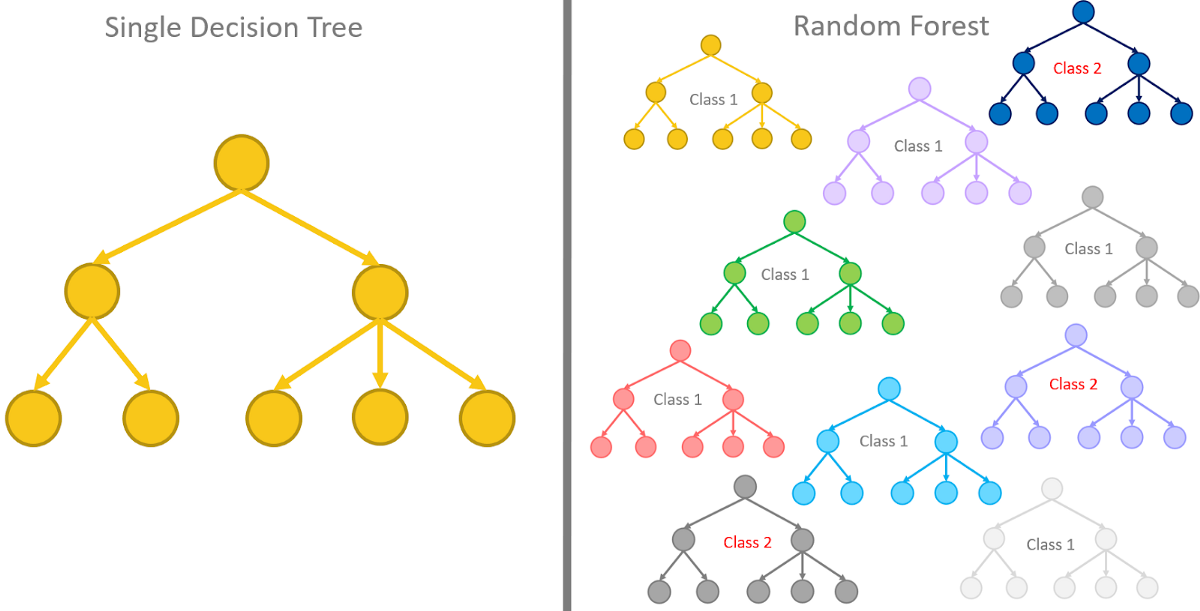
Random Forest#
A random forest is an ensemble method that builds multiple decision trees and combines their predictions. Here’s how it works:
Bootstrapping: For each tree in the forest, a subset of the training data is sampled with replacement. This helps in reducing overfitting by ensuring that each tree in the forest sees a slightly different subset of the data.
Random Feature Selection: When splitting a node, a random subset of features is considered. This further decorrelates the trees and improves generalization.
Voting or Averaging: For a classification problem, the mode of the classes predicted by individual trees is taken, and for regression, the mean prediction is used.
Pros and Cons
Pros: Reduced risk of overfitting compared to a single decision tree, often gives better predictive performance, handles missing data well.
Cons: More computationally expensive, harder to interpret because of the ensemble nature.
Difference Between Random Forest and Decision Tree
Composition: A decision tree is a single tree, while a random forest is a collection of decision trees.
Overfitting: Random forests are generally less prone to overfitting compared to individual decision trees.
Prediction: A decision tree makes a prediction based on a single path through the tree, while a random forest averages or takes a vote from multiple trees.
Computation and Interpretation: Random forests are more computationally intensive and less interpretable than individual decision trees.
In the context of SciML, both decision trees and random forests can be powerful tools. Decision trees are often used for their interpretability and simplicity, while random forests are employed for their robustness and improved predictive accuracy. Understanding the underlying mechanics and differences between these methods can help researchers and practitioners make informed choices for their specific applications.
Automatic Hyperparameter tuning#
Like we varied max_depth, there are other hyperparameters than can be tuned to improve performance.
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
Cohen’s kappa score measures the agreement between two raters/classifiers while taking into account the agreement expected by chance.
The \(\kappa\) score is calculated as:
Where:
$p_o$ is the observed agreement between raters (accuracy)
$p_e$ is the expected agreement by chance
Values range from -1 to 1, where 0 is chance level agreement and 1 is perfect agreement.
In machine learning, kappa can be used as an evaluation metric for classification models. It gives a more robust measure of performance than simple accuracy, by accounting for random chance.
GridSearchCV is a tool in sklearn to perform hyperparameter tuning. It tries out all combinations of specified hyperparameters, fits a model on each, and returns the best performing configuration based on a scoring metric (like kappa).
So in this approach, we are using GridSearchCV to optimize the hyperparameters of a Random Forest Classifier to maximize the kappa score, rather than just overall accuracy.
The goal is to tune hyperparameters like max_depth, n_estimators etc. to find the values that result in the best kappa score, indicating the model’s predictions have the strongest agreement with the true labels after accounting for chance.
This often results in a model that generalizes better than just optimizing for accuracy. The final model can then be evaluated with cross-validation to estimate real-world performance.
K-Fold Cross-Validation (CV)#
K-fold cross-validation is a popular resampling procedure used to evaluate a machine learning model’s performance.
How K-Fold CV Works:#
Partitioning: The original training data set is randomly partitioned into \( k \) equal-sized subsets or “folds.”
Training and Validation: Of the \( k \) folds, \( (k-1) \) are used for training, and one is used for validation. This is repeated \( k \) times.
Evaluation: You’ll train the model on \( (k-1) \) folds and validate it on the remaining fold, recording the error metric.
Aggregation: Average the recorded error metrics to obtain a single value that represents the model’s performance.
Benefits of K-Fold CV#
Bias-Variance Tradeoff: Good bias-variance tradeoff.
Utilizing All Data: Beneficial when dataset size is limited.
Reduction in Overfitting: Helps in detecting overfitting.
Drawbacks#
Computationally Expensive: Requires training and validating the model \( k \) times.
Randomness in Partitions: Performance estimate can be sensitive to how the data is divided.
from sklearn.model_selection import cross_val_score, GridSearchCV, cross_val_predict, KFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import cohen_kappa_score, roc_curve, roc_auc_score, accuracy_score, classification_report, make_scorer
from sklearn.ensemble import RandomForestClassifier
#define function to find best parameter combination based on Cohen’s kappa coefficient
def rfr_model(X, y):
# Perform Grid-Search
kappa_scorer = make_scorer(cohen_kappa_score)
gsc = GridSearchCV(
estimator=RandomForestClassifier(),
param_grid={
'max_depth': range(2,10),
'n_estimators': (5,10, 50, 100, 1000),
'max_features': ('auto','sqrt','log2'),
'criterion': ('gini','entropy'),
},
cv=10, verbose=0, n_jobs=-1,scoring=kappa_scorer)
grid_result = gsc.fit(X, y)
best_params = grid_result.best_params_
rfr = RandomForestClassifier(max_depth=best_params["max_depth"],
n_estimators=best_params["n_estimators"],
max_features=best_params["max_features"], criterion = best_params["criterion"])
# Perform K-Fold CV
scores = cross_val_score(rfr, X, y, cv=10)
predictions = cross_val_predict(rfr, X, y, cv=10)
optimised_random_forest = gsc.best_estimator_
print("Scores: {}", scores)
return scores, optimised_random_forest
# run optimization algorithm and print CV scores
scores, rf = rfr_model(X_train, y_train)
Scores: {} [0.77910959 0.7859589 0.79245283 0.82161235 0.7838765 0.80617496
0.78559177 0.81818182 0.80445969 0.81989708]
#print GridSearch results
print('Best parameters:', rf)
print('---')
print('CV scores:', scores)
print('CV scores (average):', np.mean(scores))
print('Training score:', rf.score(X_train, y_train))
print('Testing score:', rf.score(X_test, y_test))
Best parameters: RandomForestClassifier(max_depth=9, max_features='log2', n_estimators=1000)
---
CV scores: [0.77910959 0.7859589 0.79245283 0.82161235 0.7838765 0.80617496
0.78559177 0.81818182 0.80445969 0.81989708]
CV scores (average): 0.7997315491435419
Training score: 0.8700274348422496
Testing score: 0.7986289631533847
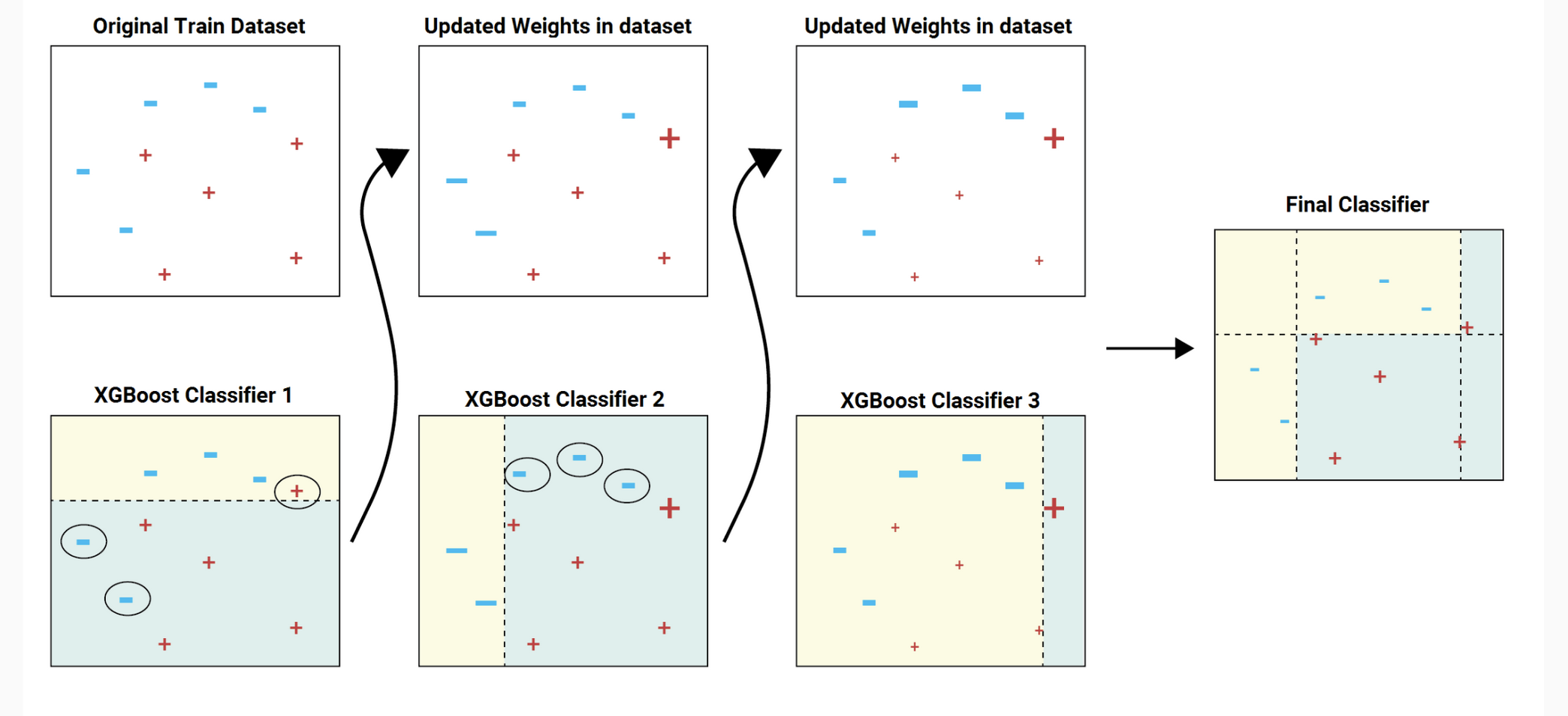
XGBoost (Extreme Gradient Boosting)#
XGBoost is a popular and efficient gradient boosting framework that’s widely used in machine learning, including in scientific contexts. It builds on the idea of boosting, where weak learners are combined to create a strong learner.
Gradient Boosting Framework#
Gradient Boosting is an ensemble learning method that fits a sequence of weak learners (such as shallow decision trees) on modified versions of the data.
The general form of the boosting model is:
Where:
\(f(x)\) is the prediction for input \( x \)
\( \alpha_k \) is the weight of the \( k \)-th weak learner
\( h_k(x) \) is the prediction of the \( k \)-th weak learner
\( K \) is the total number of weak learners
Algorithm#
Initialization: Start with a constant prediction \( f_0(x) \)
Iteratively Add Trees: For \( k = 1 \) to \( K \): a. Compute the negative gradient (or “pseudo-residuals”) of the loss function: $\( r_i = -\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)} \)\( b. Fit a weak learner to predict the pseudo-residuals. c. Compute the weight \) \alpha_k \( that minimizes the loss. d. Update the model by adding the weighted weak learner: \)\( f_k(x) = f_{k-1}(x) + \alpha_k h_k(x) \)$
XGBoost Enhancements#
XGBoost adds several enhancements to the basic gradient boosting framework:
Regularization#
XGBoost includes L1 (Lasso) and L2 (Ridge) regularization terms in the loss function to prevent overfitting:
Handling Missing Data#
XGBoost can automatically learn the best direction to handle missing values during training, allowing it to handle datasets with missing data.
Column Block and Parallelization#
XGBoost employs a column block structure that allows parallelization over both instances and features, leading to efficient computation.
Hyperparameters#
learning_rate: Step size shrinkage to prevent overfitting.
max_depth: Maximum depth of the decision trees.
n_estimators: Number of boosting rounds.
subsample: Fraction of the data to be used for each boosting round, enabling stochastic gradient boosting.
import xgboost
xgb = xgboost.XGBClassifier(max_depth=9)
xgb.fit(X_train, y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=9, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=9, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, ...)print('Training score: %.2f%%' %(xgb.score(X_train, y_train) * 100))
print('Validation score: %.2f%%' %(xgb.score(X_val, y_val) * 100))
print('Testing score: %.2f%%' %(xgb.score(X_test, y_test) * 100))
Training score: 99.69%
Validation score: 77.40%
Testing score: 85.78%
Explainable AI#
Feature Importance Metrics#
Feature importance metrics provide insights into the contribution of individual features (or variables) to a predictive model. Understanding the importance of different features can help in feature selection, model interpretation, and understanding the underlying relationships within the data.
Types of Importance Metrics#
1. Weight-Based Importance#
In models like linear regression or logistic regression, the magnitude of the coefficients can indicate the importance of features. For tree-based models like Random Forest, the importance of a feature can be calculated based on the average gain of the feature when it is used in trees.
2. Permutation Importance#
Permutation importance is a method that can be applied to any model. It is computed as follows:
a. Calculate a Performance Metric: Train the model and calculate a performance metric (such as accuracy or MSE) using a validation set. b. Permute the Feature Values: Shuffle the values of the feature of interest across the validation set, destroying the relationship between the feature and the target. c. Recompute the Performance Metric: Use the permuted data to compute the performance metric again. d. Calculate Importance: The difference between the original metric and the permuted metric provides a measure of importance.
## Compute feature importance for random forest
def plot_feature_importance(X, model):
df2=pd.get_dummies(X)
features = df2.columns
importances = model.feature_importances_
indices = np.argsort(importances)[-10:] # top 10 features
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
fi = pd.DataFrame({'feature': list(X.columns),
'importance': model.feature_importances_}).\
sort_values('importance', ascending = False)
return fi
# Display results for decision tree
plot_feature_importance(X_test, clf)
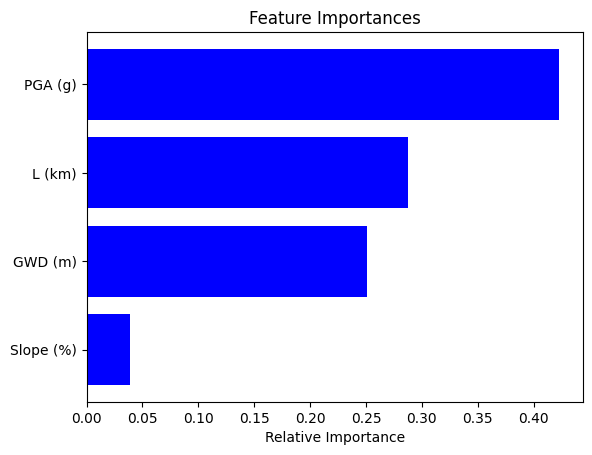
| feature | importance | |
|---|---|---|
| 3 | PGA (g) | 0.422601 |
| 1 | L (km) | 0.287876 |
| 0 | GWD (m) | 0.250497 |
| 2 | Slope (%) | 0.039026 |
# Display results for random forest
plot_feature_importance(X_test, rf)
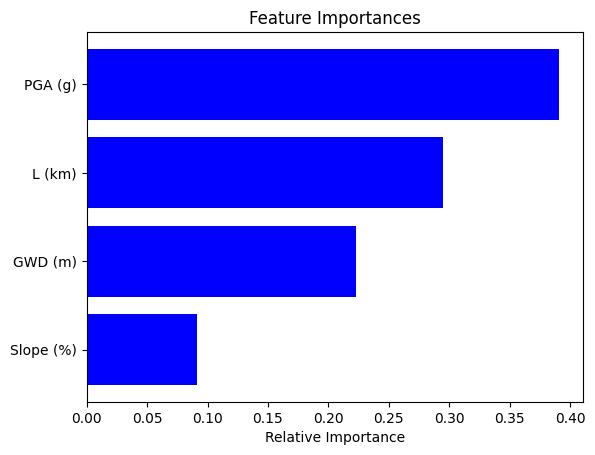
| feature | importance | |
|---|---|---|
| 3 | PGA (g) | 0.390678 |
| 1 | L (km) | 0.294591 |
| 0 | GWD (m) | 0.223014 |
| 2 | Slope (%) | 0.091718 |
# Display results for XGB
plot_feature_importance(X_test, xgb)
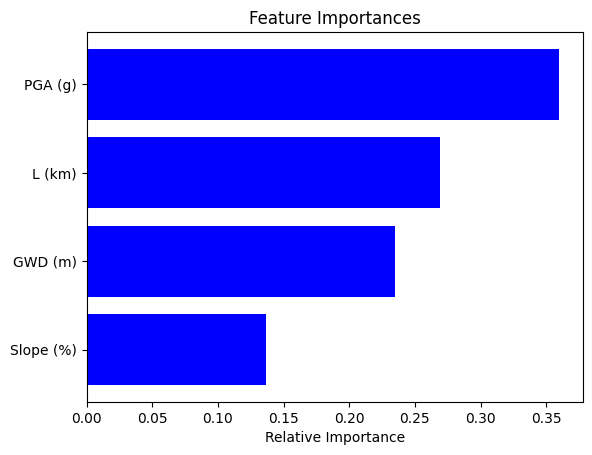
| feature | importance | |
|---|---|---|
| 3 | PGA (g) | 0.359728 |
| 1 | L (km) | 0.269205 |
| 0 | GWD (m) | 0.234558 |
| 2 | Slope (%) | 0.136509 |
3. Shapley Values#
SHAP values are based on cooperative game theory and provide a unified measure of feature importance. They give the average contribution of a feature value to every possible prediction.
For a model with \(M\) features, the Shapley value for feature \( i \) is computed as:
Where:
\( S \) is a subset of features excluding feature \( i \)
\( N \) is the set of all features
\( v(S) \) is the value function that gives the prediction for subset \( S \)
Understanding SHAP Values: An Analogy#
SHAP values help us understand how different features (or variables) contribute to a prediction in a machine learning model. To explain this without mathematics, let’s use an analogy of three team members working together on a project. Imagine that the team members are Alice, Bob, and Charlie, and we want to know how much each one contributed to the project’s success.
The Project#
The project’s success is measured by the total output, and we want to fairly distribute the credit for this success among Alice, Bob, and Charlie.
Shapley Value Concept#
Imagine breaking down the project into smaller tasks and observing how much the output changes when each team member is added or removed. The goal is to find the average contribution of each member over all possible ways the team could have been formed.
Step by Step Explanation#
No Team Members: First, we measure the output with no team members working (a baseline).
Adding One Member: Then, we add each team member one by one and measure how much the output changes.
With Alice alone
With Bob alone
With Charlie alone
Adding Two Members: Next, we measure the change in output with pairs of team members:
Alice and Bob
Alice and Charlie
Bob and Charlie
All Three Members: Finally, we measure the output with all three working together.
Calculating Contributions#
By comparing all these different combinations, we can calculate the average contribution of each team member. The SHAP value for each person is their fair share of the contribution to the project’s success.
Alice’s SHAP Value: The average change in output when Alice is part of the team.
Bob’s SHAP Value: The average change in output when Bob is part of the team.
Charlie’s SHAP Value: The average change in output when Charlie is part of the team.
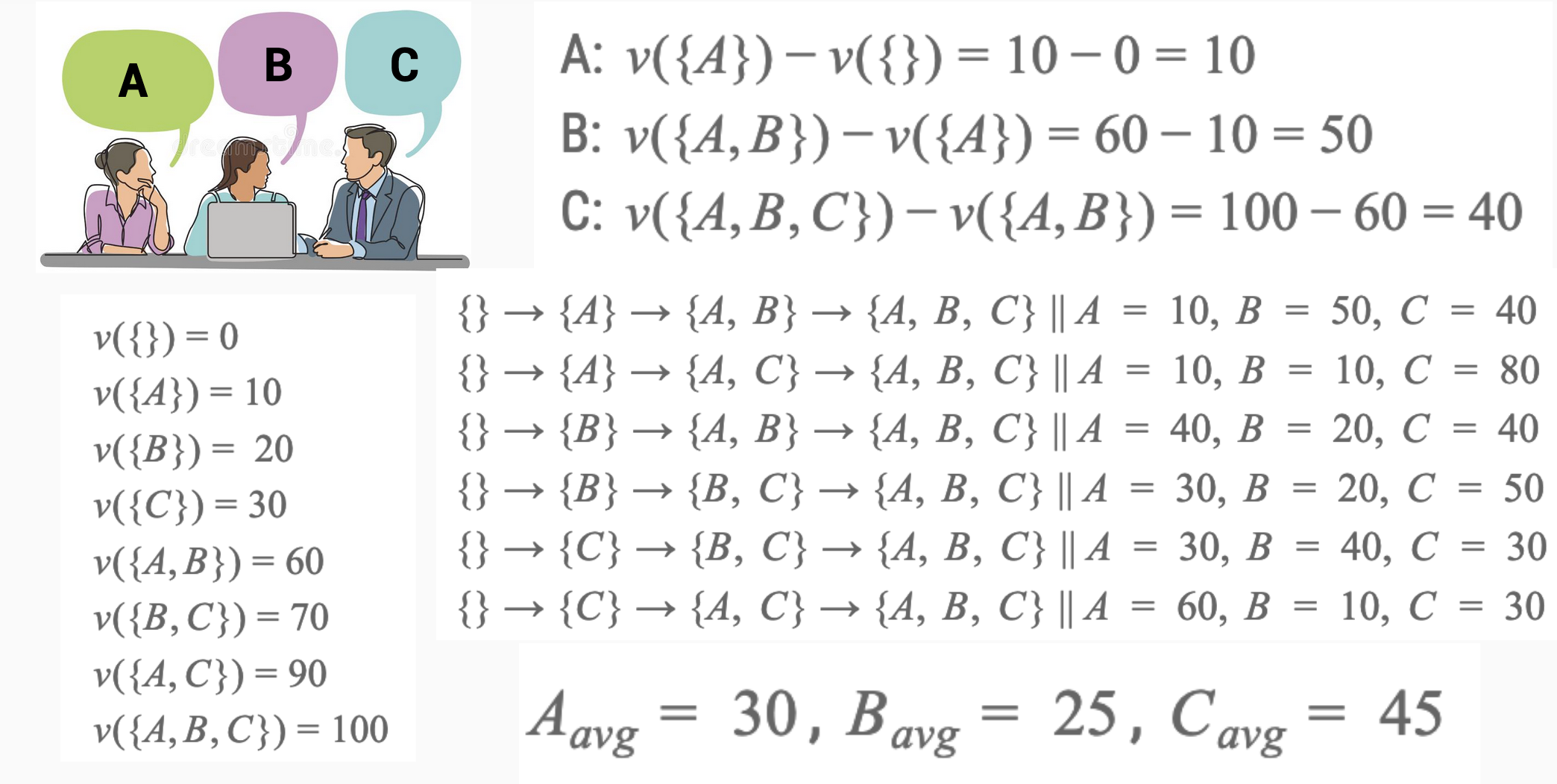
import shap
explainer = shap.TreeExplainer(xgb)
shap_values = explainer(X_test)
X_test_target.head()
| GWD (m) | L (km) | Slope (%) | PGA (g) | Target | |
|---|---|---|---|---|---|
| 182 | 1.995111 | 0.720363 | 1.056944 | 0.419531 | 0 |
| 6863 | 1.642848 | 0.287636 | 0.744498 | 0.449792 | 0 |
| 638 | 2.408738 | 1.675044 | 0.882258 | 0.495766 | 1 |
| 4770 | 1.853496 | 0.561542 | 0.044951 | 0.429180 | 1 |
| 4452 | 1.826260 | 0.518457 | 0.481842 | 0.418497 | 0 |
SHAP values are a measure used to explain the output of machine learning models. They tell us how much each feature in the model contributes to a particular prediction, compared to a baseline prediction.
Positive vs. Negative SHAP Values#
Positive SHAP Values: When a feature has a positive SHAP value, it means that the presence (or value) of that feature pushes the model’s output higher than the baseline.
Example: In our lateral spreading prediction the PGA (a feature) gives a positive SHAP value, it means that higher PGA are generally associated with higher chance of lateral spreading.
Negative SHAP Values: Conversely, when a feature has a negative SHAP value, it means that the presence (or value) of that feature pushes the model’s output lower than the baseline.
Example: Still considering lateral spreading, if water table being too low (a feature) gives a negative SHAP value, it suggests that such sites are generally predicted to have less chance of lateral spreading.
The term \(E(f(x))\) represents the expected value or average prediction of the model over the entire dataset. Think of it as the “baseline prediction.” When you see \(E(f(x))\) , it’s referring to what the model would predict on average, without considering any specific feature values.
Example: In the context of predicting house prices, \(E(f(x))\) might be the average chance of lateral spreading the model predicts when it doesn’t consider any specific features of the sites. It’s the starting point before we account for unique factors like having GWT or a high PGA.
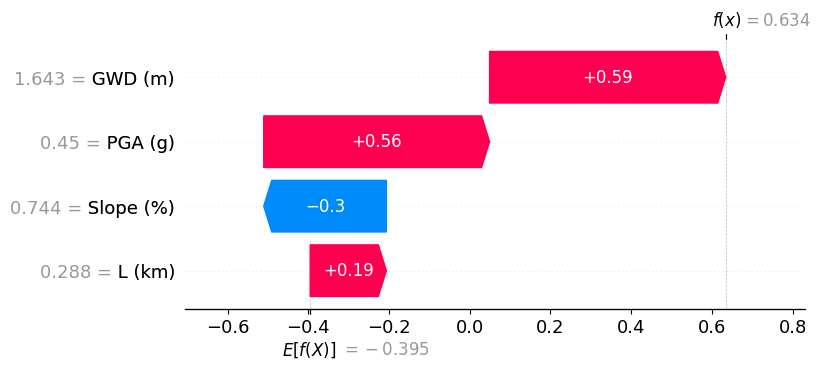
Positive prediction#
In this example, we show a site that is predicted to have positive lateral spreading (failure). Here, the high slope anlge (0.835%) has the most influence in the positive prediction of lateral spreading, followed by a shallow ground water depth of 1.8 m and its close proximity to the river (L = 0.74 km).
shap.plots.waterfall(shap_values[1])
Negative prediction#
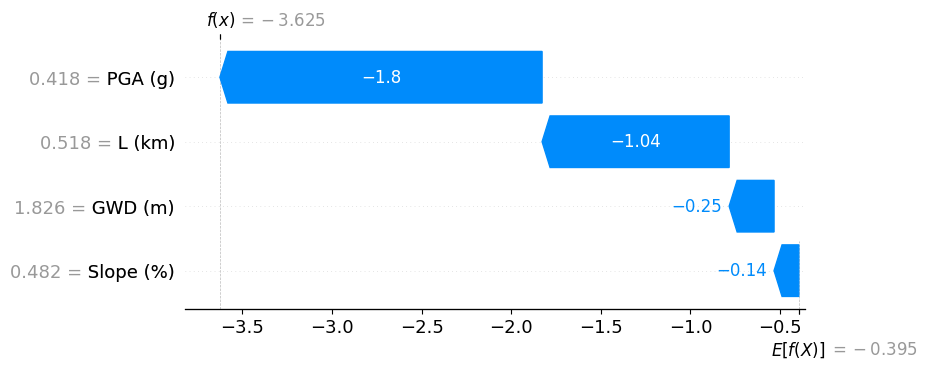
In this example, we show XGB predicting a site that has no chance of lateral spreading. The distance to the river (L ~ 2 km) seems to be the primary reason.
shap.plots.waterfall(shap_values[4])
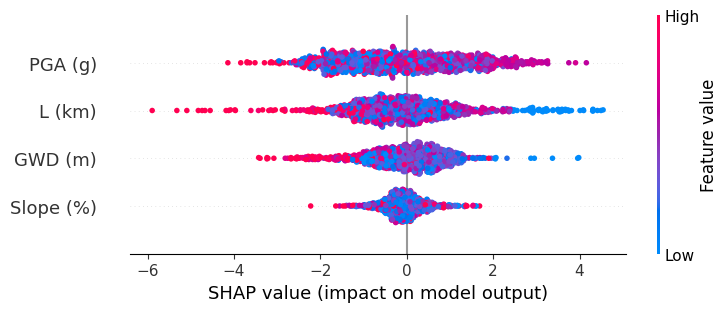
Global explanation#
We also observe global SHAP values and see how different features influence the results. High feature values are shown in red and Low feature values are shown in blue. For e.g., shorter distance to the river (blue points for \(L\)) are associated with high chance of lateral spreading. Similarly, deeper ground water depth (red GWD) means lower chances of lateral spreading.
However, we do see that high PGA, shows less chance of lateral spreading, contradictory to the engineering understanding that high acceleration will cause more displacements and failures.
shap.plots.beeswarm(shap_values)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored