06: Forward and inverse modeling of Burger’s Equation#
Exercise: ![]() Solution:
Solution: ![]()
Libraries#
#Latin Hypercube Sampling
!pip3 install pyDOE --quiet
!pip3 install urllib3 --quiet
!pip3 install scipy --quiet
import torch
import torch.autograd as autograd # computation graph
import torch.nn as nn # neural networks
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import time
from pyDOE import lhs #Latin Hypercube Sampling
import scipy.io
#Set default dtype to float32
torch.set_default_dtype(torch.float)
#PyTorch random number generator
torch.manual_seed(1234)
# Random number generators in other libraries
np.random.seed(1234)
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
if device == 'cuda':
print(torch.cuda.get_device_name())
cpu
Tunning Parameters#
steps=10000
lr=1e-1
layers = np.array([2,20,20,20,20,20,20,20,20,1]) #8 hidden layers
# Nu: Number of training points
N_u = 100 #Total number of data points for 'u'
# Nf: Number of collocation points (Evaluate PDE)
N_f = 10000 # Total number of collocation points
nu = 0.01/np.pi # diffusion coeficient
Auxiliary Functions#
def plot3D(x,t,y):
x_plot =x.squeeze(1)
t_plot =t.squeeze(1)
X,T= torch.meshgrid(x_plot,t_plot)
F_xt = y
fig,ax=plt.subplots(1,1)
cp = ax.contourf(T,X, F_xt,20,cmap="rainbow")
fig.colorbar(cp) # Add a colorbar to a plot
ax.set_title('F(x,t)')
ax.set_xlabel('t')
ax.set_ylabel('x')
plt.show()
ax = plt.axes(projection='3d')
ax.plot_surface(T.numpy(), X.numpy(), F_xt.numpy(),cmap="rainbow")
ax.set_xlabel('t')
ax.set_ylabel('x')
ax.set_zlabel('f(x,t)')
plt.show()
def plot3D_Matrix(x,t,y):
X,T= x,t
F_xt = y
fig,ax=plt.subplots(1,1)
cp = ax.contourf(T,X, F_xt,20,cmap="rainbow")
fig.colorbar(cp) # Add a colorbar to a plot
ax.set_title('F(x,t)')
ax.set_xlabel('t')
ax.set_ylabel('x')
plt.show()
ax = plt.axes(projection='3d')
ax.plot_surface(T.numpy(), X.numpy(), F_xt.numpy(),cmap="rainbow")
ax.set_xlabel('t')
ax.set_ylabel('x')
ax.set_zlabel('f(x,t)')
plt.show()
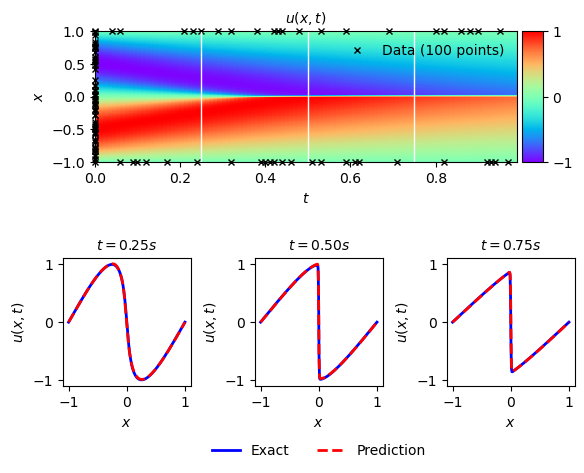
def solutionplot(u_pred,X_u_train,u_train):
# https://github.com/omniscientoctopus/Physics-Informed-Neural-Networks
fig, ax = plt.subplots()
ax.axis('off')
gs0 = gridspec.GridSpec(1, 2)
gs0.update(top=1-0.06, bottom=1-1/3, left=0.15, right=0.85, wspace=0)
ax = plt.subplot(gs0[:, :])
h = ax.imshow(u_pred, interpolation='nearest', cmap='rainbow',
extent=[T.min(), T.max(), X.min(), X.max()],
origin='lower', aspect='auto')
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
fig.colorbar(h, cax=cax)
ax.plot(X_u_train[:,1], X_u_train[:,0], 'kx', label = 'Data (%d points)' % (u_train.shape[0]), markersize = 4, clip_on = False)
line = np.linspace(x.min(), x.max(), 2)[:,None]
ax.plot(t[25]*np.ones((2,1)), line, 'w-', linewidth = 1)
ax.plot(t[50]*np.ones((2,1)), line, 'w-', linewidth = 1)
ax.plot(t[75]*np.ones((2,1)), line, 'w-', linewidth = 1)
ax.set_xlabel('$t$')
ax.set_ylabel('$x$')
ax.legend(frameon=False, loc = 'best')
ax.set_title('$u(x,t)$', fontsize = 10)
# Slices of the solution at points t = 0.25, t = 0.50 and t = 0.75
####### Row 1: u(t,x) slices ##################
gs1 = gridspec.GridSpec(1, 3)
gs1.update(top=1-1/3, bottom=0, left=0.1, right=0.9, wspace=0.5)
ax = plt.subplot(gs1[0, 0])
ax.plot(x,usol.T[25,:], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,u_pred.T[25,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$u(x,t)$')
ax.set_title('$t = 0.25s$', fontsize = 10)
ax.axis('square')
ax.set_xlim([-1.1,1.1])
ax.set_ylim([-1.1,1.1])
ax = plt.subplot(gs1[0, 1])
ax.plot(x,usol.T[50,:], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,u_pred.T[50,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$u(x,t)$')
ax.axis('square')
ax.set_xlim([-1.1,1.1])
ax.set_ylim([-1.1,1.1])
ax.set_title('$t = 0.50s$', fontsize = 10)
ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.35), ncol=5, frameon=False)
ax = plt.subplot(gs1[0, 2])
ax.plot(x,usol.T[75,:], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,u_pred.T[75,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$u(x,t)$')
ax.axis('square')
ax.set_xlim([-1.1,1.1])
ax.set_ylim([-1.1,1.1])
ax.set_title('$t = 0.75s$', fontsize = 10)
plt.savefig('Burgers.png',dpi = 500)
Foward solution to Burgers’ Equation#
Burgers’ equation is a fundamental partial differential equation (PDE) in fluid dynamics and gas dynamics. It combines nonlinear advection and linear diffusion, making it a useful equation for studying the interaction of these two processes.
The one-dimensional, unsteady, viscous Burgers’ equation is given by:
Where:
\( u = u(x,t) \) is the dependent variable (e.g., velocity in fluid dynamics).
\( x\in[-1,1] \) is the spatial coordinate.
\( t\in[0,1] \) is time.
\( \nu \) is the kinematic viscosity, which determines the strength of the diffusive term. It’s a positive constant.
There are two main terms in this equation:
Nonlinear Advection Term: \( u \frac{\partial u}{\partial x} \) – This term represents the nonlinear convective transport of the quantity \( u \). The nonlinearity arises due to the product \( u \cdot \frac{\partial u}{\partial x} \), which can lead to the formation of shock waves or steep gradients in the solution, especially in the inviscid limit (\( \nu \to 0 \)).
Diffusion Term: \( \nu \frac{\partial^2 u}{\partial x^2} \) – This term acts to smooth out sharp gradients or shocks in the solution. For higher values of \( \nu \), diffusion dominates, and the solution will be smoother.
When \( \nu = 0 \), the viscous term drops out, and the equation becomes the inviscid Burgers’ equation:
This inviscid version is hyperbolic and can develop discontinuities (shocks) from smooth initial conditions.
PDE#
Let:
\(u_t=\frac{\partial u}{\partial t}\)
\(u_x=\frac{\partial u}{\partial x}\)
\(u_{xx}=\frac{\partial^2 u}{\partial x^2}\)
So:
If we rearrange our PDE, we get:
Neural Network#
A Neural Network is a function:
Note: We usually train our NN by iteratively minimizing a loss function (\(MSE\):mean squared error) in the training dataset(known data).
PINNs=Neural Network + PDE#
(See: https://www.sciencedirect.com/science/article/pii/S0021999118307125)
We can use a neural network to approximate any function (Universal APproximation Theorem): (See:https://book.sciml.ai/notes/03/) $\(NN(x,t)\approx u(x,t)\)$
Since NN is a function, we can obtain its derivatives: \(\frac{\partial NN}{\partial t},\frac{\partial^2 NN}{\partial x^2}\).(Automatic Diferentiation)
Assume:$\(NN(t,x)\approx u(t,x)\)$
Then:
And:
We define this function as \(f\):
If \(f\rightarrow 0\) then our NN would be respecting the physical law.
PINNs’ Loss function#
We evaluate our PDE in a certain number of “collocation points” (\(N_f\)) inside our domain \((x,t)\). Then we iteratively minimize a loss function related to \(f\):
Usually, the training data set is a set of points from which we know the answer. In our case, we will use our boundary(BC) and initial conditions(IC).
Since we know the outcome, we select \(N_u\) points from our BC and IC and used them to train our network.
Total Loss:#
Neural Network#
class FCN(nn.Module):
def __init__(self,layers):
super().__init__()
self.activation = nn.Tanh()
self.loss_function = nn.MSELoss(reduction ='mean')
# Initialise neural network as a list using nn.Modulelist
self.linears = nn.ModuleList([nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1)])
self.iter = 0
# Xavier Normal Initialization
for i in range(len(layers)-1):
nn.init.xavier_normal_(self.linears[i].weight.data, gain=1.0)
# set biases to zero
nn.init.zeros_(self.linears[i].bias.data)
def forward(self,x):
if torch.is_tensor(x) != True:
x = torch.from_numpy(x)
u_b = torch.from_numpy(ub).float().to(device)
l_b = torch.from_numpy(lb).float().to(device)
# preprocessing input
x = (x - l_b)/(u_b - l_b) #feature scaling
# convert to float
a = x.float()
for i in range(len(layers)-2):
z = self.linears[i](a)
a = self.activation(z)
a = self.linears[-1](a)
return a
def loss_BC(self,x,y):
loss_u = self.loss_function(self.forward(x), y)
return loss_u
def loss_PDE(self, X_train_Nf):
g = X_train_Nf.clone()
g.requires_grad = True
u = self.forward(g)
u_x_t = autograd.grad(u,g,torch.ones([X_train_Nf.shape[0], 1]).to(device), retain_graph=True, create_graph=True)[0]
u_xx_tt = autograd.grad(u_x_t,g,torch.ones(X_train_Nf.shape).to(device), create_graph=True)[0]
u_x = u_x_t[:,[0]]
u_t = u_x_t[:,[1]]
u_xx = u_xx_tt[:,[0]]
f = u_t + (self.forward(g))*(u_x) - (nu)*u_xx
loss_f = self.loss_function(f,f_hat)
return loss_f
def loss(self,x,y,X_train_Nf):
loss_u = self.loss_BC(x,y)
loss_f = self.loss_PDE(X_train_Nf)
loss_val = loss_u + loss_f
return loss_val
def closure(self):
"""
This is often used with optimization algorithms in PyTorch that need re-evaluation of the model,
such as L-BFGS. It computes the loss, performs backpropagation, and optionally (every 100 iterations)
tests the PINN and prints the loss and the test error.
"""
optimizer.zero_grad()
loss = self.loss(X_train_Nu, U_train_Nu, X_train_Nf)
loss.backward()
self.iter += 1
if self.iter % 100 == 0:
error_vec, _ = PINN.test()
print(loss,error_vec)
return loss
# test neural network
def test(self):
u_pred = self.forward(X_test)
error_vec = torch.linalg.norm((u-u_pred),2)/torch.linalg.norm(u,2) # Relative L2 Norm of the error (Vector)
u_pred = u_pred.cpu().detach().numpy()
u_pred = np.reshape(u_pred,(256,100),order='F')
return error_vec, u_pred
Generate data#
import urllib.request
import scipy.io
import numpy as np
url = "https://github.com/kks32-courses/sciml/raw/main/lectures/06-burgers/Burgers.mat"
# Download the file
response = urllib.request.urlopen(url)
matdata = response.read()
# Write to local file
with open('burgers.mat', 'wb') as f:
f.write(matdata)
# Load Burger's mat file into dict
data = scipy.io.loadmat('burgers.mat')
x = data['x'] # 256 points between -1 and 1 [256x1]
t = data['t'] # 100 time points between 0 and 1 [100x1]
usol = data['usol'] # solution of 256x100 grid points
X, T = np.meshgrid(x,t) # makes 2 arrays X and T such that u(X[i],T[j])=usol[i][j] are a tuple
plot3D(torch.from_numpy(x),torch.from_numpy(t),torch.from_numpy(usol))
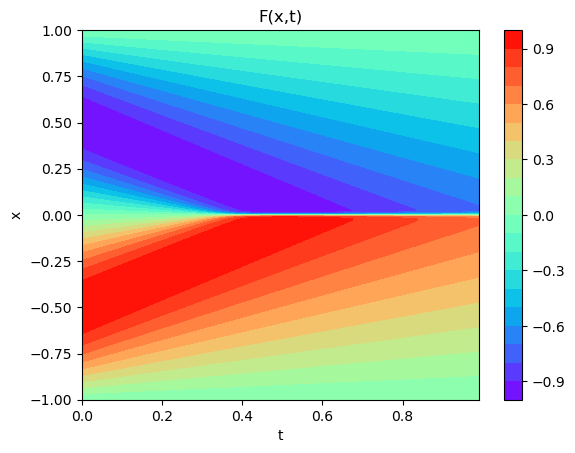
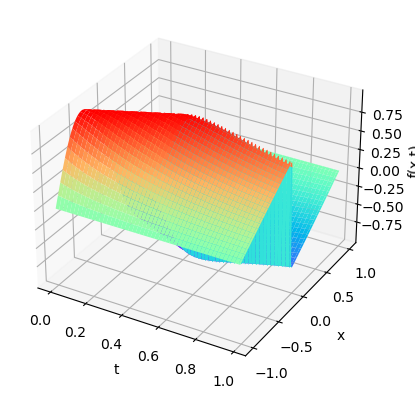
print(x.shape,t.shape,usol.shape)
print(X.shape,T.shape)
(256, 1) (100, 1) (256, 100)
(100, 256) (100, 256)
Prepare Data#
X_test = np.hstack((X.flatten()[:,None], T.flatten()[:,None]))
# Domain bounds
lb = X_test[0] # [-1. 0.]
ub = X_test[-1] # [1. 0.99]
u_true = usol.flatten('F')[:,None] #Fortran style (Column Major)
print(lb, ub)
[-1. 0.] [1. 0.99]
Training Data#
Latin Hypercube Sampling (LHS) is a statistical method designed for generating a near-random sample of parameter values from a multidimensional distribution. The main advantage of LHS over simple random sampling is that it ensures that the entire range of each parameter is adequately sampled. This makes it particularly useful for computer simulations when a multidimensional parameter space needs to be explored.
Here’s a basic outline of how Latin Hypercube Sampling works:
Divide Each Dimension: For each parameter (or dimension) you want to sample, divide the range of the parameter into NN non-overlapping intervals, where NN is the number of samples you desire. These intervals should have an equal probability of being sampled.
Random Sampling Without Replacement: For each dimension, randomly sample a value from each interval. This ensures that every interval has a sampled value. The key here is that once an interval is sampled, it cannot be sampled again (i.e., no replacement).
Randomize Across Dimensions: Combine the sampled values from all dimensions to generate a sample point. This process ensures that the sample points are randomly distributed across the entire multidimensional space.
Repeat: Repeat steps 2 and 3 until you’ve obtained the desired number of sample points.
Some key properties and advantages of LHS:
Stratification: By design, LHS guarantees that the entire range of each parameter is sampled. This stratification ensures better space-filling properties than simple random sampling.
Reduction of Clustering: Since each interval is sampled once and only once, clustering of sample points is reduced, which can be a problem in simple random sampling.
Efficiency: For many problems, LHS can be more efficient than Monte Carlo sampling, as fewer samples might be needed to achieve the same level of precision.
Flexibility: While LHS ensures even coverage of the input space, the actual sampled values within each interval are random, which provides flexibility in capturing the underlying distribution.
In many applications, especially in computational experiments where evaluating the model is expensive, Latin Hypercube Sampling provides an efficient and effective way to explore the parameter space. It’s widely used in sensitivity analysis, uncertainty analysis, and optimization problems.
# Boundary Conditions
# Initial Condition -1 =< x =<1 and t = 0
left_X = np.hstack((X[0,:][:,None], T[0,:][:,None])) #L1
left_U = usol[:,0][:,None]
# Boundary Condition x = -1 and 0 =< t =<1
bottom_X = np.hstack((X[:,0][:,None], T[:,0][:,None])) #L2
bottom_U = usol[-1,:][:,None]
# Boundary Condition x = 1 and 0 =< t =<1
top_X = np.hstack((X[:,-1][:,None], T[:,0][:,None])) #L3
top_U = usol[0,:][:,None]
X_train = np.vstack([left_X, bottom_X, top_X])
U_train = np.vstack([left_U, bottom_U, top_U])
# Choose random N_u points for training
idx = np.random.choice(X_train.shape[0], N_u, replace=False)
X_train_Nu = X_train[idx, :] # choose indices from set 'idx' (x,t)
U_train_Nu = U_train[idx,:] # choose corresponding u
# Collocation Points
# Latin Hypercube sampling for collocation points
# N_f sets of tuples(x,t)
X_train_Nf = lb + (ub-lb)*lhs(2,N_f)
X_train_Nf = np.vstack((X_train_Nf, X_train_Nu)) # append training points to collocation points
print("Original shapes for X and U:",X.shape,usol.shape)
print("Boundary shapes for the edges:",left_X.shape,bottom_X.shape,top_X.shape)
print("Available training data:",X_train.shape,U_train.shape)
print("Final training data:",X_train_Nu.shape,U_train_Nu.shape)
print("Total collocation points:",X_train_Nf.shape)
Original shapes for X and U: (100, 256) (256, 100)
Boundary shapes for the edges: (256, 2) (100, 2) (100, 2)
Available training data: (456, 2) (456, 1)
Final training data: (100, 2) (100, 1)
Total collocation points: (10100, 2)
Train Neural Network#
# Convert to tensor and send to GPU
X_train_Nf = torch.from_numpy(X_train_Nf).float().to(device)
X_train_Nu = torch.from_numpy(X_train_Nu).float().to(device)
U_train_Nu = torch.from_numpy(U_train_Nu).float().to(device)
X_test = torch.from_numpy(X_test).float().to(device)
u = torch.from_numpy(u_true).float().to(device)
f_hat = torch.zeros(X_train_Nf.shape[0],1).to(device)
PINN = FCN(layers)
PINN.to(device)
# Neural Network Summary
print(PINN)
params = list(PINN.parameters())
# L-BFGS Optimizer
optimizer = torch.optim.LBFGS(PINN.parameters(), lr,
max_iter = steps,
max_eval = None,
tolerance_grad = 1e-11,
tolerance_change = 1e-11,
history_size = 100,
line_search_fn = 'strong_wolfe')
start_time = time.time()
optimizer.step(PINN.closure)
elapsed = time.time() - start_time
print('Training time: %.2f' % (elapsed))
# Model Accuracy
error_vec, u_pred = PINN.test()
print('Test Error: %.5f' % (error_vec))
FCN(
(activation): Tanh()
(loss_function): MSELoss()
(linears): ModuleList(
(0): Linear(in_features=2, out_features=20, bias=True)
(1-7): 7 x Linear(in_features=20, out_features=20, bias=True)
(8): Linear(in_features=20, out_features=1, bias=True)
)
)
tensor(0.1166, grad_fn=<AddBackward0>) tensor(0.6768, grad_fn=<DivBackward0>)
tensor(0.0496, grad_fn=<AddBackward0>) tensor(0.4842, grad_fn=<DivBackward0>)
tensor(0.0323, grad_fn=<AddBackward0>) tensor(0.4623, grad_fn=<DivBackward0>)
tensor(0.0238, grad_fn=<AddBackward0>) tensor(0.4262, grad_fn=<DivBackward0>)
tensor(0.0149, grad_fn=<AddBackward0>) tensor(0.3887, grad_fn=<DivBackward0>)
tensor(0.0075, grad_fn=<AddBackward0>) tensor(0.3375, grad_fn=<DivBackward0>)
tensor(0.0039, grad_fn=<AddBackward0>) tensor(0.2753, grad_fn=<DivBackward0>)
tensor(0.0020, grad_fn=<AddBackward0>) tensor(0.1771, grad_fn=<DivBackward0>)
tensor(0.0011, grad_fn=<AddBackward0>) tensor(0.1224, grad_fn=<DivBackward0>)
tensor(0.0007, grad_fn=<AddBackward0>) tensor(0.0584, grad_fn=<DivBackward0>)
tensor(0.0004, grad_fn=<AddBackward0>) tensor(0.0244, grad_fn=<DivBackward0>)
tensor(0.0003, grad_fn=<AddBackward0>) tensor(0.0284, grad_fn=<DivBackward0>)
tensor(0.0002, grad_fn=<AddBackward0>) tensor(0.0282, grad_fn=<DivBackward0>)
tensor(0.0002, grad_fn=<AddBackward0>) tensor(0.0278, grad_fn=<DivBackward0>)
tensor(0.0001, grad_fn=<AddBackward0>) tensor(0.0325, grad_fn=<DivBackward0>)
tensor(0.0001, grad_fn=<AddBackward0>) tensor(0.0332, grad_fn=<DivBackward0>)
tensor(0.0001, grad_fn=<AddBackward0>) tensor(0.0345, grad_fn=<DivBackward0>)
tensor(8.1510e-05, grad_fn=<AddBackward0>) tensor(0.0332, grad_fn=<DivBackward0>)
tensor(6.8506e-05, grad_fn=<AddBackward0>) tensor(0.0360, grad_fn=<DivBackward0>)
tensor(6.0551e-05, grad_fn=<AddBackward0>) tensor(0.0369, grad_fn=<DivBackward0>)
tensor(5.4207e-05, grad_fn=<AddBackward0>) tensor(0.0382, grad_fn=<DivBackward0>)
tensor(4.9783e-05, grad_fn=<AddBackward0>) tensor(0.0350, grad_fn=<DivBackward0>)
tensor(4.4510e-05, grad_fn=<AddBackward0>) tensor(0.0332, grad_fn=<DivBackward0>)
tensor(3.9261e-05, grad_fn=<AddBackward0>) tensor(0.0326, grad_fn=<DivBackward0>)
tensor(3.5546e-05, grad_fn=<AddBackward0>) tensor(0.0298, grad_fn=<DivBackward0>)
tensor(3.1453e-05, grad_fn=<AddBackward0>) tensor(0.0266, grad_fn=<DivBackward0>)
tensor(2.8191e-05, grad_fn=<AddBackward0>) tensor(0.0257, grad_fn=<DivBackward0>)
tensor(2.6016e-05, grad_fn=<AddBackward0>) tensor(0.0251, grad_fn=<DivBackward0>)
tensor(2.3360e-05, grad_fn=<AddBackward0>) tensor(0.0255, grad_fn=<DivBackward0>)
tensor(2.0078e-05, grad_fn=<AddBackward0>) tensor(0.0228, grad_fn=<DivBackward0>)
tensor(1.8544e-05, grad_fn=<AddBackward0>) tensor(0.0244, grad_fn=<DivBackward0>)
tensor(1.6839e-05, grad_fn=<AddBackward0>) tensor(0.0235, grad_fn=<DivBackward0>)
tensor(1.5309e-05, grad_fn=<AddBackward0>) tensor(0.0234, grad_fn=<DivBackward0>)
tensor(1.4373e-05, grad_fn=<AddBackward0>) tensor(0.0223, grad_fn=<DivBackward0>)
tensor(1.3535e-05, grad_fn=<AddBackward0>) tensor(0.0228, grad_fn=<DivBackward0>)
tensor(1.2260e-05, grad_fn=<AddBackward0>) tensor(0.0235, grad_fn=<DivBackward0>)
tensor(1.1435e-05, grad_fn=<AddBackward0>) tensor(0.0238, grad_fn=<DivBackward0>)
tensor(1.0757e-05, grad_fn=<AddBackward0>) tensor(0.0242, grad_fn=<DivBackward0>)
tensor(1.0028e-05, grad_fn=<AddBackward0>) tensor(0.0237, grad_fn=<DivBackward0>)
tensor(9.4967e-06, grad_fn=<AddBackward0>) tensor(0.0243, grad_fn=<DivBackward0>)
tensor(9.1489e-06, grad_fn=<AddBackward0>) tensor(0.0244, grad_fn=<DivBackward0>)
tensor(8.7480e-06, grad_fn=<AddBackward0>) tensor(0.0245, grad_fn=<DivBackward0>)
tensor(8.4033e-06, grad_fn=<AddBackward0>) tensor(0.0249, grad_fn=<DivBackward0>)
tensor(8.1312e-06, grad_fn=<AddBackward0>) tensor(0.0242, grad_fn=<DivBackward0>)
tensor(7.9274e-06, grad_fn=<AddBackward0>) tensor(0.0247, grad_fn=<DivBackward0>)
tensor(7.6622e-06, grad_fn=<AddBackward0>) tensor(0.0250, grad_fn=<DivBackward0>)
tensor(7.4923e-06, grad_fn=<AddBackward0>) tensor(0.0244, grad_fn=<DivBackward0>)
Training time: 207.31
Test Error: 0.02438
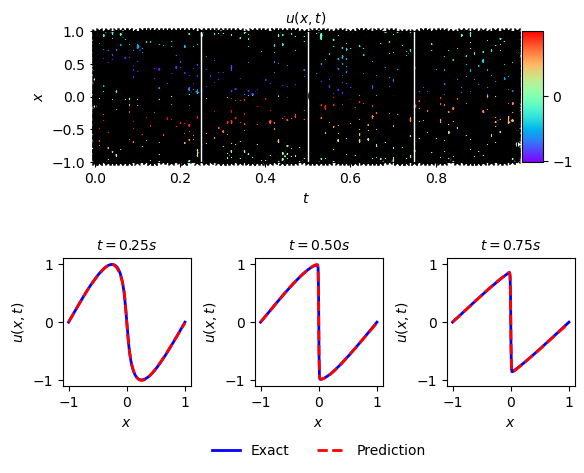
solutionplot(u_pred,X_train_Nu.cpu().detach().numpy(),U_train_Nu)
/var/folders/6k/lmrc2s553fq0vn7c57__f37r0000gn/T/ipykernel_42557/2764407204.py:9: MatplotlibDeprecationWarning: Auto-removal of overlapping axes is deprecated since 3.6 and will be removed two minor releases later; explicitly call ax.remove() as needed.
ax = plt.subplot(gs0[:, :])
Plots#
x1=X_test[:,0]
t1=X_test[:,1]
arr_x1=x1.reshape(shape=X.shape).transpose(1,0).detach().cpu()
arr_T1=t1.reshape(shape=X.shape).transpose(1,0).detach().cpu()
arr_y1=u_pred
arr_y_test=usol
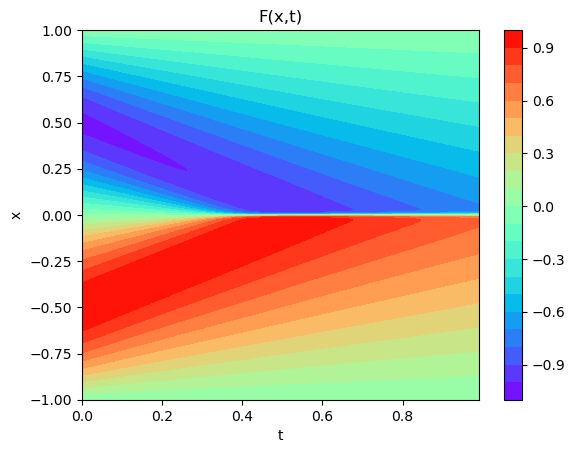
plot3D_Matrix(arr_x1,arr_T1,torch.from_numpy(arr_y1))
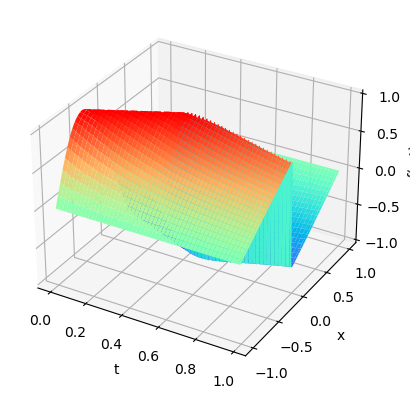
plot3D(torch.from_numpy(x),torch.from_numpy(t),torch.from_numpy(usol))
Inverse Solution to Burger’s Equation#
Inverse Problems#
Forward Problem: Model \(\rightarrow\) Data (Predict)
Inverse Problem: Data \(\rightarrow\) Model (i.e., actually, we get the Model’s parameters)
A Neural Network is an example of an inverse problem:
We have an unknown model that follows:
We use our “training” data to get \(W_i\) and \(b_i\); for \(i=1,2,..\#layers\).
Specifically:
Data \(\rightarrow\) Model i.e., estimate our model parameters (i,e., \(W_i\) and \(b_i\))
PINNs for Inverse Problems or “Data-driven Discovery of Nonlinear Partial Differential Equations”#
(See: https://arxiv.org/abs/1711.10566)
Inverse Problem: Data \(\rightarrow\) Model’s parameters so:
Data \(\rightarrow\) PINN \(\rightarrow\) Model Parameters (i.e., our PDE parameters)
For parameterized and nonlinear partial differential equations of the general form (Raissi et al., 2017):
where, \(u(x,t)\) is the hidden solution and \(\mathscr{N}[;\lambda]\) is a nonlinear operator parameterized by \(\lambda\).
In short: We will use a PINN to get \(\lambda\).
Let:
\(u_t=\frac{\partial u}{\partial t}\)
\(u_x=\frac{\partial u}{\partial x}\)
\(u_{xx}=\frac{\partial^2 u}{\partial x^2}\)
\(\mathscr{N}[u;\lambda]=\lambda_1u u_x-\lambda_2 u_{xx}\)
Our PDE is described as:
If we rearrange our PDE, we get:
Or,
So we can use a PINN to obtain \(\lambda\)!
In our case (from the reference solution) \(\lambda=[\lambda_1,\lambda_2]=[1,\nu]=\left[1,\frac{1}{100\pi}\right]\)
Neural Network#
A Neural Network is a function:
Note: We usually train our N by iteratively minimizing a loss function in the training dataset(known data) to get \(W_i\) and \(b_i\).
PINNs=Neural Network + PDE#
(See: https://www.sciencedirect.com/science/article/pii/S0021999118307125)
We can use a neural network to approximate any function (Universal APproximation Theorem): (See:https://book.sciml.ai/notes/03/) $\(N(x,t)\approx u(x,t)\)$
Since N(x,t) is a function, we can obtain its derivatives: \(\frac{\partial N}{\partial t},\frac{\partial^2 N}{\partial x^2}, etc.\).(Automatic Diferentiation)
Assume:$\(N(t,x)\approx u(t,x)\)$
Then:
And:
We define this function as \(f\):
Remember our operator:
So:
PINNs’ Loss function#
We evaluate \(f\) in a certain number of points (\(N_u\)) inside our domain \((x,t)\). Then we iteratively minimize a loss function related to \(f\):
Usually, the training data set is a set of points from which we know the answer. In our case, points inside our domain (i.e., interior points). Remember that this is an inverse problem, so we know the data.
Since we know the outcome, we select \(N\) and compute the \(MSE_u\)** (compare it to the reference solution).
Please note that \(\{t_u^i,x_u^i\}_{i=1}^N\) are the same in \(MSE_f\) and \(MSE_u\)
Total Loss:#
NOTE: We minimize \(MSE\) to obtain the \(N\)’s parameters (i.e, \(W_i\) and \(b_i\)) and the ODE parameters (i.e., \(\lambda\))\(\rightarrow\) We will ask our neural network to find our \(\lambda\).
Neural Network#
# Deep Neural Network
class DNN(nn.Module):
def __init__(self,layers):
super().__init__() #call __init__ from parent class
self.activation = nn.Tanh()
self.linears = nn.ModuleList([nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1)])
for i in range(len(layers)-1):
nn.init.xavier_normal_(self.linears[i].weight.data, gain=1.0)
# set biases to zero
nn.init.zeros_(self.linears[i].bias.data)
def forward(self,x):
if torch.is_tensor(x) != True:
x = torch.from_numpy(x)
u_b = torch.from_numpy(ub).float().to(device)
l_b = torch.from_numpy(lb).float().to(device)
#preprocessing input
x = (x - l_b)/(u_b - l_b) #feature scaling
#convert to float
a = x.float()
for i in range(len(layers)-2):
z = self.linears[i](a)
a = self.activation(z)
a = self.linears[-1](a)
return a
Initialize our parameters#
Our operator is:
We know that:
lambda1=2.0
lambda2=0.2
print("Te real 𝜆 = [", 1.0,nu,"]. Our initial guess will be 𝜆 _PINN= [",lambda1,lambda2,"]")
Te real 𝜆 = [ 1.0 0.003183098861837907 ]. Our initial guess will be 𝜆 _PINN= [ 2.0 0.2 ]
# PINN
class FCN():
def __init__(self, layers):
self.loss_function = nn.MSELoss(reduction ='mean')
# Initialize iterator
self.iter = 0
# Initialize our new parameters i.e. 𝜆 (Inverse problem)
self.lambda1 = torch.tensor([lambda1], requires_grad=True).float().to(device)
self.lambda2 = torch.tensor([lambda2], requires_grad=True).float().to(device)
# Register lambda to optimize
self.lambda1 = nn.Parameter(self.lambda1)
self.lambda2 = nn.Parameter(self.lambda2)
# Call our DNN
self.dnn = DNN(layers).to(device)
# Register our new parameter
self.dnn.register_parameter('lambda1', self.lambda1)
self.dnn.register_parameter('lambda2', self.lambda2)
def loss_data(self,x,y):
loss_u = self.loss_function(self.dnn(x), y)
return loss_u
def loss_PDE(self, X_train_Nu):
lambda1=self.lambda1
lambda2=self.lambda2
g = X_train_Nu.clone()
g.requires_grad = True
u = self.dnn(g)
u_x_t = autograd.grad(u,g,torch.ones([X_train_Nu.shape[0], 1]).to(device), retain_graph=True, create_graph=True)[0]
u_xx_tt = autograd.grad(u_x_t,g,torch.ones(X_train_Nu.shape).to(device), create_graph=True)[0]
u_x = u_x_t[:,[0]]
u_t = u_x_t[:,[1]]
u_xx = u_xx_tt[:,[0]]
f = u_t + (lambda1)*(self.dnn(g))*(u_x) - (lambda2)*u_xx
loss_f = self.loss_function(f,f_hat)
return loss_f
def loss(self,x,y):
loss_u = self.loss_data(x,y)
loss_f = self.loss_PDE(x)
loss_val = loss_u + loss_f
return loss_val
def closure(self):
optimizer.zero_grad()
loss = self.loss(X_train_Nu, U_train_Nu)
loss.backward()
self.iter += 1
if self.iter % 100 == 0:
error_vec, _ = PINN.test()
print(
'Relative Error(Test): %.5f , 𝜆_real = [1.0, %.5f], 𝜆_PINN = [%.5f, %.5f]' %
(
error_vec.cpu().detach().numpy(),
nu,
self.lambda1.item(),
self.lambda2.item()
)
)
return loss
# test neural network
def test(self):
u_pred = self.dnn(X_true)
error_vec = torch.linalg.norm((U_true-u_pred),2)/torch.linalg.norm(U_true,2) # Relative L2 Norm of the error (Vector)
u_pred = u_pred.cpu().detach().numpy()
u_pred = np.reshape(u_pred,(x.shape[0],t.shape[0]),order='F')
return error_vec, u_pred
Visualize the data#
x = data['x'] # 256 points between -1 and 1 [256x1]
t = data['t'] # 100 time points between 0 and 1 [100x1]
usol = data['usol'] # solution of 256x100 grid points
X, T = np.meshgrid(x,t) # makes 2 arrays X and T such that u(X[i],T[j])=usol[i][j] are a tuple
plot3D(torch.from_numpy(x),torch.from_numpy(t),torch.from_numpy(usol))
print(x.shape,t.shape,usol.shape)
print(X.shape,T.shape)
(256, 1) (100, 1) (256, 100)
(100, 256) (100, 256)
Prepare Data#
X_true = np.hstack((X.flatten()[:,None], T.flatten()[:,None]))
# Domain bounds
lb = X_true[0] # [-1. 0.]
ub = X_true[-1] # [1. 0.99]
U_true = usol.flatten('F')[:,None] # (Column Major)
print(lb,ub)
[-1. 0.] [1. 0.99]
Training data#
total_points=len(x)*len(t)
# Obtain random points for interior
id_f = np.random.choice(total_points, N_f, replace=False)# Randomly chosen points for Interior
X_train_Nu = X_true[id_f]
U_train_Nu= U_true[id_f]
print("We have",total_points,"points. We will select",X_train_Nu.shape[0],"points to train our model.")
print("Original shapes for X and U:",X.shape,usol.shape)
print("Final training data:",X_train_Nu.shape,U_train_Nu.shape)
We have 25600 points. We will select 10000 points to train our model.
Original shapes for X and U: (100, 256) (256, 100)
Final training data: (10000, 2) (10000, 1)
Train Neural Network#
# 'Convert our arrays to tensors and send them to our GPU'
X_train_Nu = torch.from_numpy(X_train_Nu).float().to(device)
U_train_Nu = torch.from_numpy(U_train_Nu).float().to(device)
X_true = torch.from_numpy(X_true).float().to(device)
U_true = torch.from_numpy(U_true).float().to(device)
f_hat = torch.zeros(X_train_Nu.shape[0],1).to(device)
layers = np.array([2,20,20,20,20,20,20,20,20,1]) #8 hidden layers
PINN = FCN(layers)
# Neural Network Summary
print(PINN)
params = list(PINN.dnn.parameters())
## Optimization
### L-BFGS Optimizer
optimizer = torch.optim.LBFGS(params, lr,
max_iter = steps,
max_eval = None,
tolerance_grad = 1e-11,
tolerance_change = 1e-11,
history_size = 100,
line_search_fn = 'strong_wolfe')
start_time = time.time()
optimizer.step(PINN.closure)
elapsed = time.time() - start_time
print('Training time: %.2f' % (elapsed))
# Model Accuracy
error_vec, u_pred = PINN.test()
print('Test Error: %.5f' % (error_vec))
<__main__.FCN object at 0x28f414910>
Relative Error(Test): 0.44295 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [1.49775, 0.11306]
Relative Error(Test): 0.25372 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.44212, 0.00753]
Relative Error(Test): 0.22287 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.39770, 0.00654]
Relative Error(Test): 0.18655 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.48637, 0.00484]
Relative Error(Test): 0.16718 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.59808, 0.00643]
Relative Error(Test): 0.15538 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.63584, 0.00662]
Relative Error(Test): 0.13024 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.76241, 0.00758]
Relative Error(Test): 0.11696 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.80833, 0.00698]
Relative Error(Test): 0.11013 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.79486, 0.00769]
Relative Error(Test): 0.10208 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.81663, 0.00893]
Relative Error(Test): 0.08756 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.86894, 0.00803]
Relative Error(Test): 0.07833 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.88040, 0.00754]
Relative Error(Test): 0.06850 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.87600, 0.00657]
Relative Error(Test): 0.06512 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.87118, 0.00605]
Relative Error(Test): 0.05733 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.88411, 0.00553]
Relative Error(Test): 0.05315 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.90638, 0.00551]
Relative Error(Test): 0.04634 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.93545, 0.00553]
Relative Error(Test): 0.04213 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.94059, 0.00535]
Relative Error(Test): 0.04175 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.94792, 0.00540]
Relative Error(Test): 0.04046 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.94197, 0.00518]
Relative Error(Test): 0.03778 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.93887, 0.00488]
Relative Error(Test): 0.03512 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.95411, 0.00484]
Relative Error(Test): 0.03433 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96262, 0.00477]
Relative Error(Test): 0.02887 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96885, 0.00438]
Relative Error(Test): 0.02753 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96838, 0.00428]
Relative Error(Test): 0.02678 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97101, 0.00422]
Relative Error(Test): 0.02650 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97045, 0.00420]
Relative Error(Test): 0.02596 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96590, 0.00413]
Relative Error(Test): 0.02510 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96874, 0.00413]
Relative Error(Test): 0.02479 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96424, 0.00404]
Relative Error(Test): 0.02408 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.96851, 0.00398]
Relative Error(Test): 0.02422 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97129, 0.00400]
Relative Error(Test): 0.02295 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97510, 0.00396]
Relative Error(Test): 0.02273 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97912, 0.00397]
Relative Error(Test): 0.02224 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97685, 0.00395]
Relative Error(Test): 0.02151 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97482, 0.00392]
Relative Error(Test): 0.02043 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97663, 0.00385]
Relative Error(Test): 0.02042 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97660, 0.00384]
Relative Error(Test): 0.01996 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97917, 0.00386]
Relative Error(Test): 0.01862 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97980, 0.00380]
Relative Error(Test): 0.01871 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97864, 0.00380]
Relative Error(Test): 0.01813 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97910, 0.00377]
Relative Error(Test): 0.01784 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97932, 0.00375]
Relative Error(Test): 0.01783 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97967, 0.00376]
Relative Error(Test): 0.01789 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97770, 0.00374]
Relative Error(Test): 0.01738 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97771, 0.00371]
Relative Error(Test): 0.01714 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97741, 0.00371]
Relative Error(Test): 0.01691 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97621, 0.00372]
Relative Error(Test): 0.01647 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97740, 0.00368]
Relative Error(Test): 0.01681 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97390, 0.00365]
Relative Error(Test): 0.01699 , 𝜆_real = [1.0, 0.00318], 𝜆_PINN = [0.97337, 0.00364]
Training time: 259.18
Test Error: 0.01699
Plots#
solutionplot(u_pred,X_train_Nu.cpu().detach().numpy(),U_train_Nu)
/var/folders/6k/lmrc2s553fq0vn7c57__f37r0000gn/T/ipykernel_42557/2764407204.py:9: MatplotlibDeprecationWarning: Auto-removal of overlapping axes is deprecated since 3.6 and will be removed two minor releases later; explicitly call ax.remove() as needed.
ax = plt.subplot(gs0[:, :])
x1=X_true[:,0]
t1=X_true[:,1]
arr_x1=x1.reshape(shape=X.shape).transpose(1,0).detach().cpu()
arr_T1=t1.reshape(shape=X.shape).transpose(1,0).detach().cpu()
plot3D_Matrix(arr_x1,arr_T1,torch.from_numpy(u_pred))
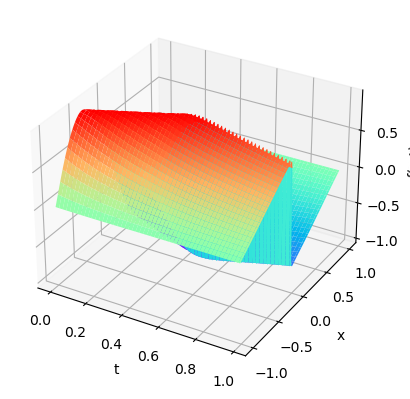
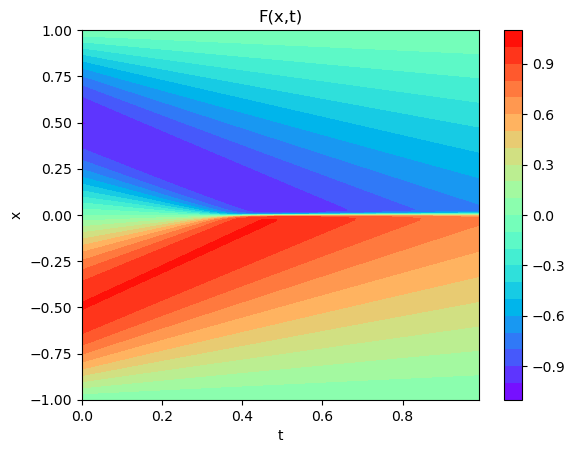
plot3D(torch.from_numpy(x),torch.from_numpy(t),torch.from_numpy(usol))
References:#
[1] Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2017). Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations. arXiv preprint arXiv:1711.10561. http://arxiv.org/pdf/1711.10561v1
[2] Lu, L., Meng, X., Mao, Z., & Karniadakis, G. E. (1907). DeepXDE: A deep learning library for solving differential equations,(2019). URL http://arxiv. org/abs/1907.04502. https://arxiv.org/abs/1907.04502
[3] Rackauckas Chris, Introduction to Scientific Machine Learning through Physics-Informed Neural Networks. https://book.sciml.ai/notes/03/
[4] Repository: Physics-Informed-Neural-Networks (PINNs).omniscientoctopus/Physics-Informed-Neural-Networks’%20Equation
[5] Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2017). Physics Informed Deep Learning (part ii): Data-driven Discovery of Nonlinear Partial Differential Equations. arXiv preprint arXiv:1711.10566. https://arxiv.org/abs/1711.10566
[6] Repository: PPhysics-Informed Deep Learning and its Application in Computational Solid and Fluid Mechanics.alexpapados/Physics-Informed-Deep-Learning-Solid-and-Fluid-Mechanics.