09: Physics-Informed DeepONet#
Exercise: ![]() Solution:
Solution: ![]()
Physics-informed DeepONets#
Similar to a PINN, a Physics-informed DeepONets output functions consistent with physical constraints by minimizing the residual of an underlying governing law (i.e., nonlinear differential operator).
where \(\mathcal{N}\) is a nonlinear differential operator, and \(\{y_j\}_{i=1}^{Q}\) are the collocation points ( we use them to enforce the physical constraint).
So the total loss would be:
In summary:
To train a DeepOnet, we would:
We select \(N\) functions →\(u(x)\).
We evaluate our \(N\) functions at \(m\) points (i.e., input sensors) →\(u(x_1),u(x_2),...,u(x_m)\)
We send the \(m\) outputs of our \(N\) functions to our branch network → \(b_k(u(x_1),u(x_2),...,u(x_m))\)
We select \(P\) points (i.e., output sensors) inside our domain → \(y_1,y_2,...,y_P\)
We send our output sensors to our trunk network→\(t_k(y_1,y_2,...,y_P)\)
We approximate our operator by computing the dot product between the outpur of our branch network and the output of our trunk network→ \(G_\theta(u)(y)=\sum_{k=1}^q\underset{Branch}{\underbrace{b_k\left(u(x_1),u(x_2),...,u(x_m)\right)}}.\underset{Trunk}{\underbrace{t_k(\textbf{y})}}\)
Ideally \(G_\theta(u)(y)\approx G(u)(y)\), so we compute the error → \(\mathcal{L}(\theta)=\frac{1}{NP}\sum_{i=1}^N\sum_{j=1}^P\left|G_{\theta}(u^{(i)})y_j^{(i)}-G(u^{(i)})y_j^{(i)}\right|^2\)
We update our NN parameters (i.e., branch and trunk) to minimize \(\mathcal{L}(\theta)\).
We repeat the process.
Problem Setup#
Anti-derivative Operator
Our PDE would be:
The solution of our PDE is:
In this example, lets concider \(Q=m\) and \(\{y_j^{(i)}\}_{j=1}^Q\). Hence, the physics loss can be formulated as:
import numpy as onp
import jax.numpy as np
from jax import random, grad, vmap, jit
from jax.example_libraries import optimizers
from jax.experimental.ode import odeint
from jax.nn import relu
from jax.config import config
import itertools
from functools import partial
from torch.utils import data
from tqdm import trange
import matplotlib.pyplot as plt
%matplotlib inline
# Define RBF kernel
def RBF(x1, x2, params):
output_scale, lengthscales = params
diffs = np.expand_dims(x1 / lengthscales, 1) - \
np.expand_dims(x2 / lengthscales, 0)
r2 = np.sum(diffs**2, axis=2)
return output_scale * np.exp(-0.5 * r2)
def plot_us(x,u,y,s):
fig, ax1 = plt.subplots(figsize=(8, 6))
plt.rcParams['font.size'] = '18'
color='black'
wdt=1.5
ax1.plot(x,u,'k--',label='$u(x)=ds/dx$',linewidth=wdt)
ax1.plot(y,s,'o-',label='$s(x)=s(0)+\int u(t)dt|_{t=y}$',linewidth=wdt)
ax1.set_xlabel('x',fontsize='large')
ax1.set_ylabel('u',fontsize='large')
ax1.tick_params(axis='y', color=color)
ax1.legend(loc = 'lower right', ncol=1)
Data Generation#
We will randomly sample 10000 different functions \(u\) from a zero-mean Gaussian process with an exponential quadratic kernel with a length scale: \(l=0.2\).
N_train = 10000
m = 100 # number of input sensors
P_train = 1 # number of output sensors
length_scale = 0.2 #lenght_scale for the exponential quadratic kernel
key_train = random.PRNGKey(0) # use different key for generating training data and test data
config.update("jax_enable_x64", True) # Enable double precision
Generate a random function#
# Sample GP prior at a fine grid
N = 512
gp_params = (1.0, length_scale)
jitter = 1e-10
X = np.linspace(0, 1, N)[:,None]
K = RBF(X, X, gp_params)
L = np.linalg.cholesky(K + jitter*np.eye(N))
gp_sample = np.dot(L, random.normal(key_train, (N,)))
# Create a callable interpolation function
u_fn = lambda x, t: np.interp(t, X.flatten(), gp_sample)
# Input sensor locations and measurements
x = np.linspace(0, 1, m)
u = vmap(u_fn, in_axes=(None,0))(0.0, x) #vectorize our code to run it in multiple batches simultaneusly (or to evaluate a function simultaneusly)
We obtain the corresponding 10000 ODE solutions by solving:
Using an explicit Runge-Kutta method(RK45)→ JAX’s odeint functiom.
# Output sensor locations and measurements
y_train = random.uniform(key_train, (P_train*100,)).sort()
s_train = odeint(u_fn, 0.0, y_train) # Obtain the ODE solution
plot_us(x,u,y_train,s_train)
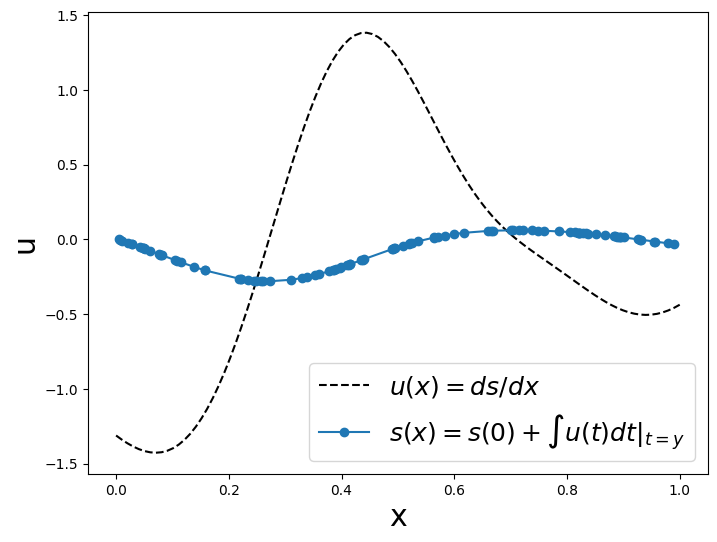
Now, we will have to create many functions for our testing and training dataset, so let’s create a pair of programing-functions to generate one random function at a time.
# Geneate training data corresponding to one input sample
def generate_one_training_data(key, m=100, P=1):
# Sample GP prior at a fine grid
N = 512
gp_params = (1.0, length_scale)
jitter = 1e-10
X = np.linspace(0, 1, N)[:,None]
K = RBF(X, X, gp_params)
L = np.linalg.cholesky(K + jitter*np.eye(N))
gp_sample = np.dot(L, random.normal(key, (N,)))
# Create a callable interpolation function
u_fn = lambda x, t: np.interp(t, X.flatten(), gp_sample)
# Input sensor locations and measurements
x = np.linspace(0, 1, m)
u = vmap(u_fn, in_axes=(None,0))(0.0, x)
# Output sensor locations and measurements
y_train = random.uniform(key, (P,)).sort()
s_train = odeint(u_fn, 0.0, np.hstack((0.0, y_train)))[1:] # JAX has a bug and always returns s(0), so add a dummy entry to y and return s[1:]
# Tile inputs
u_train = np.tile(u, (P,1))
# training data for the residual
u_r_train = np.tile(u, (m, 1))
y_r_train = x
s_r_train = u
return u_train, y_train, s_train, u_r_train, y_r_train, s_r_train
# Geneate test data corresponding to one input sample
def generate_one_test_data(key, m=100, P=100):
# Sample GP prior at a fine grid
N = 512
gp_params = (1.0, length_scale)
jitter = 1e-10
X = np.linspace(0, 1, N)[:,None]
K = RBF(X, X, gp_params)
L = np.linalg.cholesky(K + jitter*np.eye(N))
gp_sample = np.dot(L, random.normal(key, (N,)))
# Create a callable interpolation function
u_fn = lambda x, t: np.interp(t, X.flatten(), gp_sample)
# Input sensor locations and measurements
x = np.linspace(0, 1, m)
u = vmap(u_fn, in_axes=(None,0))(0.0, x)
# Output sensor locations and measurements
y = np.linspace(0, 1, P)
s = odeint(u_fn, 0.0, y)
# Tile inputs
u = np.tile(u, (P,1))
return u, y, s
Data Generation#
# Training Data
N_train = 10000 #Number of functions
m = 100 # number of input sensors
P_train = 1 # number of output sensors
key_train = random.PRNGKey(0) # use different key for generating training data and test data
config.update("jax_enable_x64", True) # Enable double precision
keys = random.split(key_train, N_train) # Obtain 10000 random numbers
gen_fn = jit(lambda key: generate_one_training_data(key, m, P_train)) # Call the function that generates functions
u_train, y_train, s_train, u_r_train, y_r_train, s_r_train = vmap(gen_fn)(keys)
# Reshape the data
u_train = np.float32(u_train.reshape(N_train * P_train,-1))
y_train = np.float32(y_train.reshape(N_train * P_train,-1))
s_train = np.float32(s_train.reshape(N_train * P_train,-1))
u_r_train = np.float32(u_r_train.reshape(N_train * m,-1))
y_r_train = np.float32(y_r_train.reshape(N_train * m,-1))
s_r_train = np.float32(s_r_train.reshape(N_train * m,-1))
# Testing Data
N_test = 1 # number of input samples
P_test = m # number of sensors
key_test = random.PRNGKey(12345) # A different key
keys = random.split(key_test, N_test)
gen_fn = jit(lambda key: generate_one_test_data(key, m, P_test))
u, y, s = vmap(gen_fn)(keys)
#Reshape the data
u_test = np.float32(u.reshape(N_test * P_test,-1))
y_test = np.float32(y.reshape(N_test * P_test,-1))
s_test = np.float32(s.reshape(N_test * P_test,-1))
# Data generator
class DataGenerator(data.Dataset):
def __init__(self, u, y, s,
batch_size=64, rng_key=random.PRNGKey(1234)):
'Initialization'
self.u = u # input sample
self.y = y # location
self.s = s # labeled data evulated at y (solution measurements, BC/IC conditions, etc.)
self.N = u.shape[0]
self.batch_size = batch_size
self.key = rng_key
def __getitem__(self, index):
'Generate one batch of data'
self.key, subkey = random.split(self.key)
inputs, outputs = self.__data_generation(subkey)
return inputs, outputs
@partial(jit, static_argnums=(0,))
def __data_generation(self, key):
'Generates data containing batch_size samples'
idx = random.choice(key, self.N, (self.batch_size,), replace=False)
s = self.s[idx,:]
y = self.y[idx,:]
u = self.u[idx,:]
# Construct batch
inputs = (u, y)
outputs = s
return inputs, outputs
DeepOnet#
# Define the neural net
def MLP(layers, activation=relu):
''' Vanilla MLP'''
def init(rng_key):
def init_layer(key, d_in, d_out):
k1, k2 = random.split(key)
glorot_stddev = 1. / np.sqrt((d_in + d_out) / 2.)
W = glorot_stddev * random.normal(k1, (d_in, d_out))
b = np.zeros(d_out)
return W, b
key, *keys = random.split(rng_key, len(layers))
params = list(map(init_layer, keys, layers[:-1], layers[1:]))
return params
def apply(params, inputs):
for W, b in params[:-1]:
outputs = np.dot(inputs, W) + b
inputs = activation(outputs)
W, b = params[-1]
outputs = np.dot(inputs, W) + b
return outputs
return init, apply
# Define the model
class PI_DeepONet:
def __init__(self, branch_layers, trunk_layers):
# Network initialization and evaluation functions
self.branch_init, self.branch_apply = MLP(branch_layers, activation=np.tanh)
self.trunk_init, self.trunk_apply = MLP(trunk_layers, activation=np.tanh)
# Initialize
branch_params = self.branch_init(rng_key = random.PRNGKey(1234))
trunk_params = self.trunk_init(rng_key = random.PRNGKey(4321))
params = (branch_params, trunk_params)
# Use optimizers to set optimizer initialization and update functions
self.opt_init, \
self.opt_update, \
self.get_params = optimizers.adam(optimizers.exponential_decay(1e-3,
decay_steps=1000,
decay_rate=0.9))
self.opt_state = self.opt_init(params)
self.itercount = itertools.count()
# Loggers
self.loss_log = []
self.loss_operator_log = []
self.loss_physics_log = []
# Define DeepONet architecture
def operator_net(self, params, u, y):
branch_params, trunk_params = params
B = self.branch_apply(branch_params, u)
T = self.trunk_apply(trunk_params, y)
outputs = np.sum(B * T)
return outputs
# Define ODE/PDE residual
def residual_net(self, params, u, y):
# computes gradient with respect to second argument `y`
s_y = grad(self.operator_net, argnums = 2)(params, u, y)
return s_y
# Define operator loss
def loss_operator(self, params, batch):
# Fetch data
# inputs: (u, y), shape = (N, m), (N,1)
# outputs: s, shape = (N,1)
inputs, outputs = batch
u, y = inputs
# Compute forward pass
pred = vmap(self.operator_net, (None, 0, 0))(params, u, y)
# Compute loss
loss = np.mean((outputs.flatten() - pred.flatten())**2)
return loss
# Define physics loss
def loss_physics(self, params, batch):
# Fetch data
# inputs: (u_r, y_r), shape = (NxQ, m), (NxQ,1)
# outputs: s_r, shape = (NxQ, 1)
inputs, outputs = batch
u, y = inputs
# Compute forward pass
pred = vmap(self.residual_net, (None, 0, 0))(params, u, y)
# Compute loss
loss = np.mean((outputs.flatten() - pred.flatten())**2)
return loss
# Define total loss
def loss(self, params, operator_batch, physics_batch):
loss_operator = self.loss_operator(params, operator_batch)
loss_physics = self.loss_physics(params, physics_batch)
loss = loss_operator + loss_physics
return loss
# Define a compiled update step
@partial(jit, static_argnums=(0,))
def step(self, i, opt_state, operator_batch, physics_batch):
params = self.get_params(opt_state)
g = grad(self.loss)(params, operator_batch, physics_batch)
return self.opt_update(i, g, opt_state)
# Optimize parameters in a loop
def train(self, operator_dataset, physics_dataset, nIter = 10000):
# Define the data iterator
operator_data = iter(operator_dataset)
physics_data = iter(physics_dataset)
pbar = trange(nIter)
# Main training loop
for it in pbar:
operator_batch= next(operator_data)
physics_batch = next(physics_data)
self.opt_state = self.step(next(self.itercount), self.opt_state, operator_batch, physics_batch)
if it % 100 == 0:
params = self.get_params(self.opt_state)
# Compute losses
loss_value = self.loss(params, operator_batch, physics_batch)
loss_operator_value = self.loss_operator(params, operator_batch)
loss_physics_value = self.loss_physics(params, physics_batch)
# Store losses
self.loss_log.append(loss_value)
self.loss_operator_log.append(loss_operator_value)
self.loss_physics_log.append(loss_physics_value)
# Print losses during training
pbar.set_postfix({'Loss': loss_value,
'loss_operator' : loss_operator_value,
'loss_physics': loss_physics_value})
# Evaluates predictions at test points
@partial(jit, static_argnums=(0,))
def predict_s(self, params, U_star, Y_star):
s_pred = vmap(self.operator_net, (None, 0, 0))(params, U_star, Y_star)
return s_pred
@partial(jit, static_argnums=(0,))
def predict_s_y(self, params, U_star, Y_star):
s_y_pred = vmap(self.residual_net, (None, 0, 0))(params, U_star, Y_star)
return s_y_pred
Evaluate our Operator#
# Initialize model
# For vanilla DeepONet, shallower network yields better accuarcy.
branch_layers = [m, 50, 50, 50, 50, 50]
trunk_layers = [1, 50, 50, 50, 50, 50]
model = PI_DeepONet(branch_layers, trunk_layers)
# Create data set
batch_size = 10000
operator_dataset = DataGenerator(u_train, y_train, s_train, batch_size)
physics_dataset = DataGenerator(u_r_train, y_r_train, s_r_train, batch_size)
# Train
model.train(operator_dataset, physics_dataset, nIter=40000)
100%|██████████| 40000/40000 [31:28<00:00, 21.18it/s, Loss=3.25504492146338e-05, loss_operator=9.499975938724936e-07, loss_physics=3.160045e-05]
# Predict
params = model.get_params(model.opt_state)
s_pred = model.predict_s(params, u_test, y_test)[:,None]
s_y_pred = model.predict_s_y(params, u_test, y_test) # remember that s_y=ds/dy=u
# Compute relative l2 error
error_s = np.linalg.norm(s_test - s_pred) / np.linalg.norm(s_test)
error_u = np.linalg.norm(u_test[::P_test].flatten()[:,None] - s_y_pred) / np.linalg.norm(u_test[::P_test].flatten()[:,None])
print(error_s,error_u)
0.0032120440180003207 0.0037780148
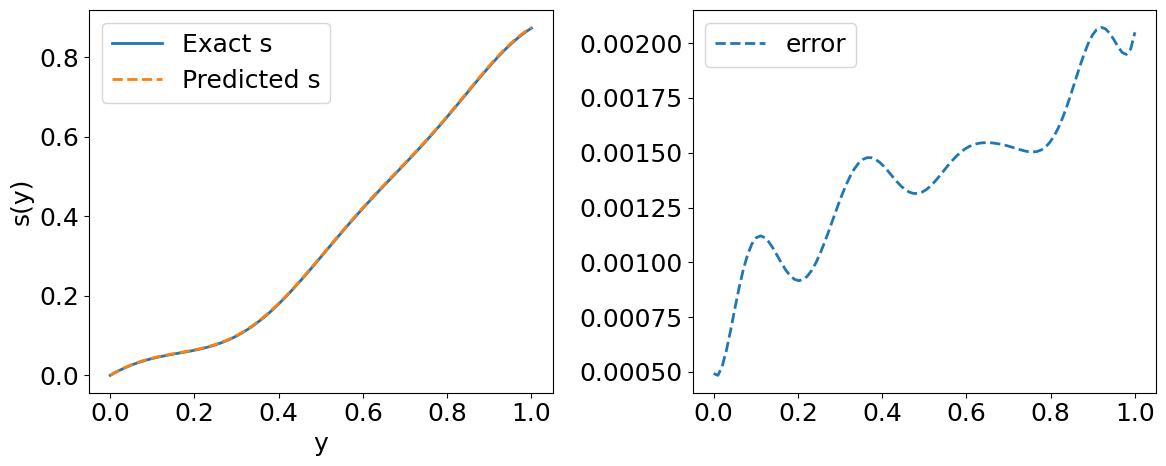
Visualize the results for the first function in our Testing Dataset#
idx=0
index = np.arange(idx * P_test,(idx + 1) * P_test)
# Compute the relative l2 error for one input sample
error_u = np.linalg.norm(s_test[index, :] - s_pred[index, :], 2) / np.linalg.norm(s_test[index, :], 2)
error_s = np.linalg.norm(u_test[::P_test][idx].flatten()[:,None] - s_y_pred[index, :], 2) / np.linalg.norm(u_test[::P_test][idx].flatten()[:,None], 2)
print("error_u: {:.3e}".format(error_u))
print("error_s: {:.3e}".format(error_s))
# Visualizations
# Predicted solution s(y)
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(y_test[index, :], s_test[index, :], label='Exact s', lw=2)
plt.plot(y_test[index, :], s_pred[index, :], '--', label='Predicted s', lw=2)
plt.xlabel('y')
plt.ylabel('s(y)')
plt.tight_layout()
plt.legend()
plt.subplot(1,2,2)
plt.plot(y_test[index, :], s_pred[index, :] - s_test[index, :], '--', lw=2, label='error')
plt.tight_layout()
plt.legend()
plt.show()
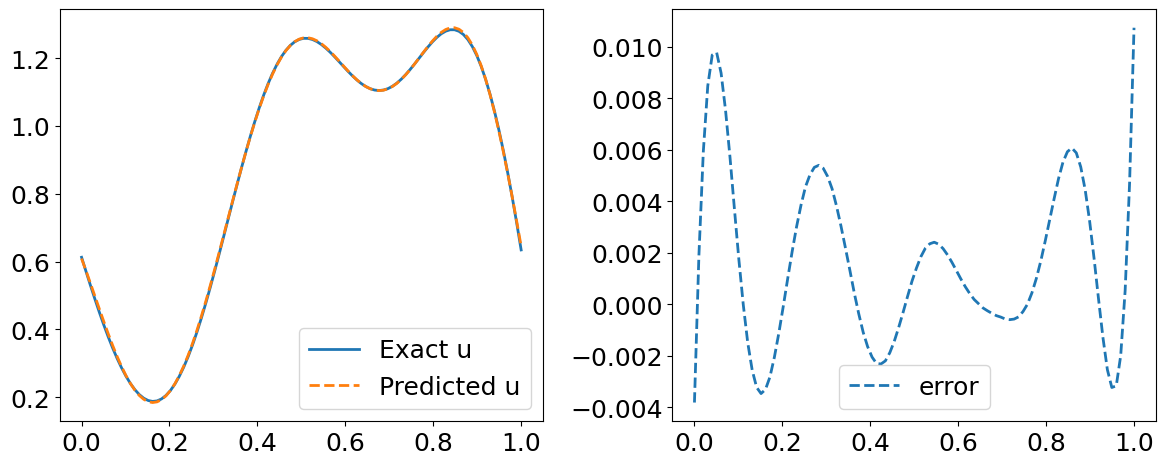
# Predicted residual u(x)
fig = plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(y_test[index, :], u_test[::P_test][idx], label='Exact u', lw=2)
plt.plot(y_test[index, :], s_y_pred[index,:], '--', label='Predicted u', lw=2)
plt.legend()
plt.tight_layout()
plt.subplot(1,2,2)
plt.plot(y_test[index, :], s_y_pred[index,:].flatten() - u_test[::P_test][idx] , '--', label='error', lw=2)
plt.legend()
plt.tight_layout()
plt.show()
error_u: 3.212e-03
error_s: 3.778e-03
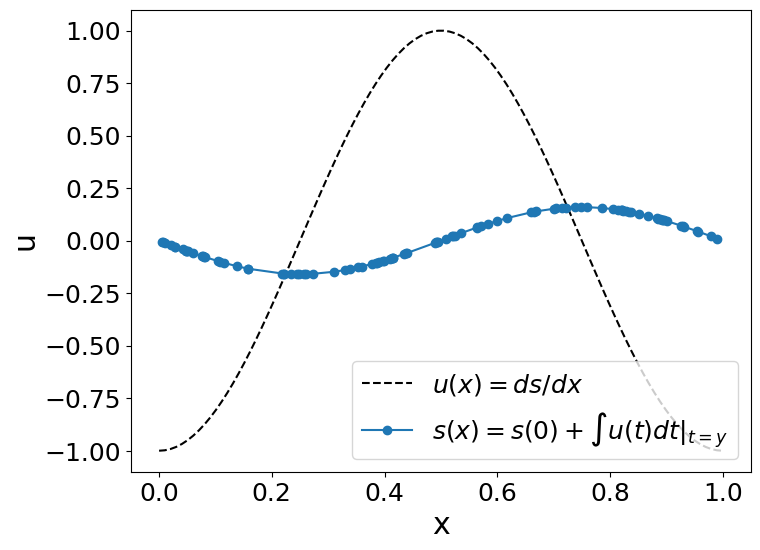
Example#
Lets obtain the anti-derivative of a trigonometric function. However, remember that this neural operator works for \(x\in[0,1]\) when the antiderivative’s initial value (\(s(0)=0\)). To fulfill that conditions, we will use \(u(x)=cos(2\pi x),∀x\in[0,1]\).
So, we will evaluate our operator (\(G\)):
to \(u(t)=cos(2\pi t)\):
Since \(s(0)=0\), the answer would be (the integral of u):
#u_fn = lambda x, t: np.interp(t, X.flatten(), gp_sample)
u_fn = lambda t, x: -np.cos(2*np.pi*x)
# Input sensor locations and measurements
x = np.linspace(0, 1, m)
u = u_fn(None,x)
# Output sensor locations and measurements
y =random.uniform(key_train, (m,)).sort()
# reshapte the data to be processed by our DeepOnet
u2=np.tile(u,100)
u2=np.float32(u2.reshape(N_test * P_test,-1))
y=y.reshape(len(y),1)
s=model.predict_s(params, u2, y)[:,None]
plot_us(x,u,y,s)
References#
[1] Lu, L., Jin, P., & Karniadakis, G. E. (2019). Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193.
[2] Wang, S., Wang, H., & Perdikaris, P. (2021). Learning the solution operator of parametric partial differential equations with physics-informed DeepONets. Science advances, 7(40), eabi8605.